处理组件
Langflow 的 处理 组件在流程中处理和转换数据。 它们有许多用途,包括:
- 使用 提示模板 组件 为您的 LLM 和代理提供指令和上下文。
- 使用 解析器 组件 从更大的数据块中提取内容。
- 使用 智能函数 组件 通过自然语言过滤数据。
- 使用 保存文件 组件 将数据保存到本地计算机。
- 使用 类型转换 组件 将数据转换为不同的数据类型,以便在不兼容的组件之间传递。
提示模板
请参阅 提示模板 组件。
批量运行
批量运行 组件在 DataFrame 的 单个文本列的每一行 上运行语言模型,然后返回一个新的 DataFrame,其中包含原始文本和 LLM 响应。
输出包含以下列:
text_input: 来自输入DataFrame的原始文本model_response: 每个输入的模型响应batch_index:DataFrame中所有行的 0 索引处理顺序metadata(可选): 关于处理的附加信息
在流程中使用批�量运行组件
如果您将 批量运行 的输出传递给 解析器 组件,您可以在解析模板中使用变量来引用这些键,例如 {text_input} 和 {model_response}。
以下示例演示了这一点。
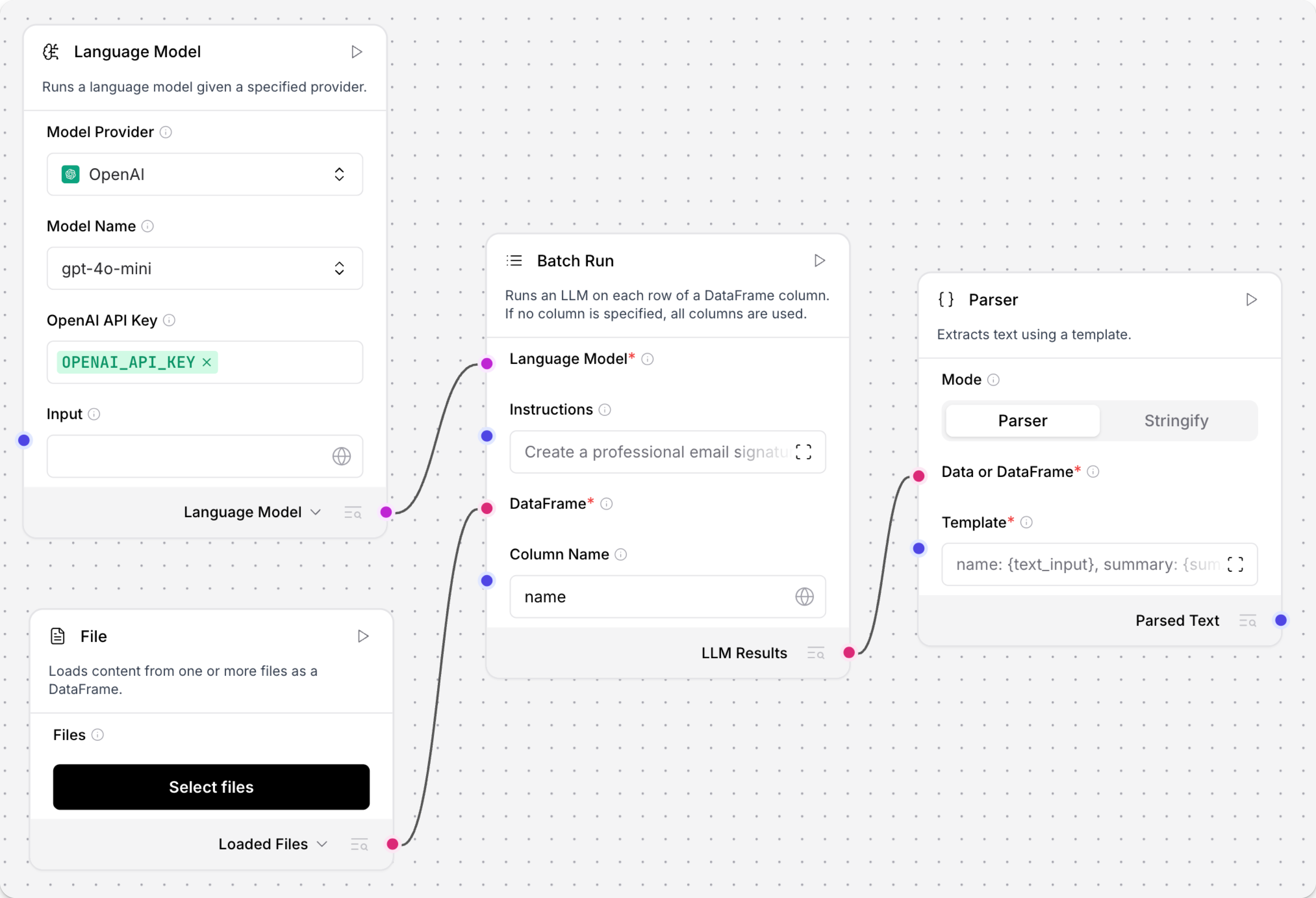
-
将 语言模型 组件连接到 批量运行 组件的 语言模型 端口。
-
将来自另一个组件的
DataFrame输出连接到 批量运行 组件的 DataFrame 输入。 例如,您可以连接一个包含 CSV 文件的 文件 组件。 -
在 批量运行 组件的 列名 字段中,输入传入的
DataFrame中包含要处理的文本的列名。 例如,如果您想从 CSV 文件的name列中提取文本,请在 列名 字段中输入name。 -
将 批量运行 组件的 批量结果 输出连接到 解析器 组件的 DataFrame 输入。
-
可选:在 批量运行 组件的标题菜单 中,点击 控制,启用 系统消息 参数,点击 关闭,然后输入您希望 LLM 如何处理从文件中提取的每个单元格的指令。 例如,
为每个名称创建名片。 -
在 解析器 组件的 模板 字段中,输入一个用于处理 批量运行 组件的新
DataFrame列(text_input、model_response和batch_index)的模板:例如,此模板使用批量处理后结果
DataFrame中的三列:_10记录编号: {batch_index}, 名称: {text_input}, 摘要: {model_response} -
要测试处理,点击 解析器 组件,点击 运行组件,然后点击 检查输出 以查看最终的
DataFrame。如果您想在 游乐场 中查看输出,也可以将 聊天输出 组件连接到 解析器 组件。
批量运行参数
在可视化编辑器中,部分参数默认情况下是隐藏的。 您可以通过组件的头部菜单中的 控件 来修改所有参数。
| 名称 | 类型 | 描述 |
|---|---|---|
| model | HandleInput | 输入参数。连接来自 语言模型 组件的 '语言模型' 输出。必需。 |
| system_message | MultilineInput | 输入参数。针对 DataFrame 中所有行的多行系统指令。 |
| df | DataFrameInput | 输入参数。其列被视为文本消息的 DataFrame,由 'column_name' 指定。必需。 |
| column_name | MessageTextInput | 输入参数。被视为文本消息的 DataFrame 列名。如果为空,所有列将以 TOML 格式化。 |
| output_column_name | MessageTextInput | 输入参数。存储模型响应的列名。默认=model_response。 |
| enable_metadata | BoolInput | 输入参数。如果为 True,则向输出 DataFrame 添加元数据。 |
| batch_results | DataFrame | 输出参数。包含所有原始列加上模型响应列的 DataFrame。 |
数据操作
数据操作组件对 Data 对象执行操作,包括在 Data 中提取、过滤和编辑键和值。
有关所有选项,请参阅可用的数据操作。
输出是一个新的 Data 对象,其中包含运行选定操作后修改的数据。
在流程中使用数据操作组件
以下示例演示了如何使用来自 webhook 负载数据的 数据操作 组件在流程中使用:
-
创建一个包含 Webhook 组件和 数据操作 组件的流程,然后将 Webhook 组件的输出连接到 数据操作 组件的 Data 输入。
数据操作 组件中的所有操作都需要至少一个来自其他组件的
Data输入。 如果前一个组件不产生Data输出,您可以使用另一个组件(如 Type Convert 组件)在将数据传递给 数据操作 组件之前重新格式化数据。 或者,您可以考虑使用专门用于处理原始数据类型的组件,如 Parser 或 DataFrame Operations 组件。 -
在 Operations 字段中,选择要对传入的
Data执行的操作。 对于此示例,选择 Select Keys 操作。提示您只能选择一个操作。 如果需要对数据执行多个操作,可以将多个 数据操作 组件链接在一起,以顺序执行每个操作。 对于更复杂的多步操作,请考虑使用类似 Smart Function 组件的组件。
-
在 Select Keys 下,为
name、username和email添加键。 点击 Add more 为每个键添加一个字段。对于此示例,假设 webhook 将接收始终包含
name、username和email键的一致负载。 Select Keys 操作从每个传入负载中提取这些键的值。 -
可选:如果要在 Playground 中查看输出,请将 数据操作 组件的输出连接到 Chat Output 组件。
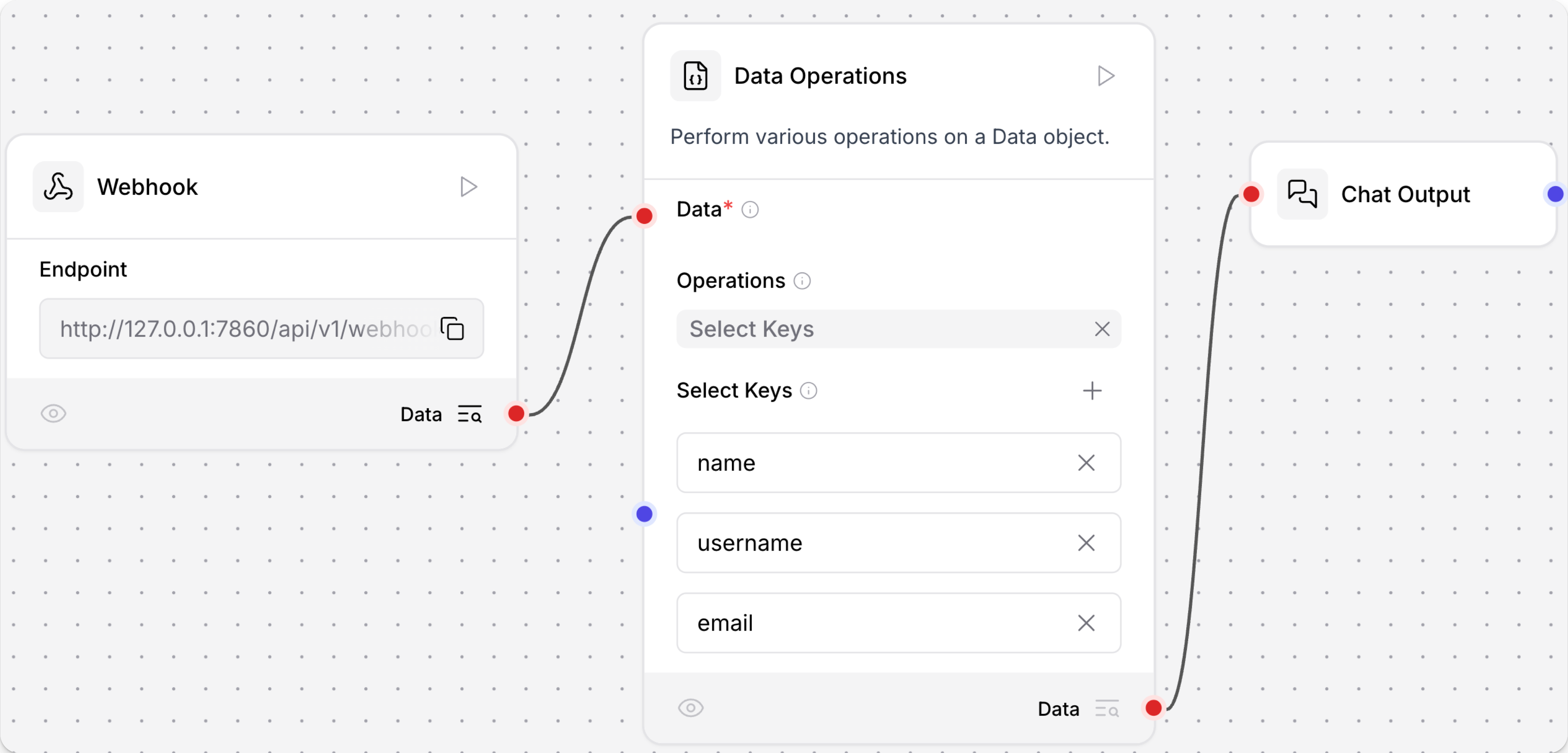
-
要测试流程,请将以下请求发送到您的流程 webhook 端点。 有关 webhook 端点的更多信息,请参阅使用 webhook 触发流程。
_26curl -X POST "http://$LANGFLOW_SERVER_URL/api/v1/webhook/$FLOW_ID" \_26-H "Content-Type: application/json" \_26-H "x-api-key: $LANGFLOW_API_KEY" \_26-d '{_26"id": 1,_26"name": "Leanne Graham",_26"username": "Bret",_26"email": "[email protected]",_26"address": {_26"street": "Main Street",_26"suite": "Apt. 556",_26"city": "Springfield",_26"zipcode": "92998-3874",_26"geo": {_26"lat": "-37.3159",_26"lng": "81.1496"_26}_26},_26"phone": "1-770-736-8031 x56442",_26"website": "hildegard.org",_26"company": {_26"name": "Acme-Corp",_26"catchPhrase": "Multi-layered client-server neural-net",_26"bs": "harness real-time e-markets"_26}_26}' -
要查看 Select Keys 操作产生的
Data,请执行以下操作之一:- 如果您附加了 Chat Output 组件,请打开 Playground 以聊天消息的形式查看结果。
- 在 数据操作 组件上点击 Inspect output。
数据操作参数
许多参数基于所选的 Operation (operation) 条件化。
| Name | Display Name | Info |
|---|---|---|
| data | Data | 输入参数。要操作的 Data 对象。 |
| operation | Operation | 输入参数。要对数据执行的操作。请参阅可用的数据操作 |
| select_keys_input | Select Keys | 输入参数。要从数据中选择键的列表。 |
| filter_key | Filter Key | 输入参数。要按其筛选的键。 |
| operator | Comparison Operator | 输入参数。用于比较值的运算符。 |
| filter_values | Filter Values | 输入参数。要按其筛选的值列表。 |
| append_update_data | Append or Update | 输入参数。要追加或更新现有数据的数据。 |
| remove_keys_input | Remove Keys | 输入参数。要从数据中移除的键列表。 |
| rename_keys_input | Rename Keys | 输入参数。要在数据中重命名的键列表。 |
可用的数据操作
operations 输入参数的选项如下。
所有操作都作用于传入的 Data 对象。
| 名称 | 必需输入 | 处理过程 |
|---|---|---|
| 选择键 | select_keys_input | 从数据中选择特定的键。 |
| 字面量求值 | 无 | 将字符串值作为 Python 字面量进行求值。 |
| 合并 | 无 | 将多个数据对象合并为一个。 |
| 过滤值 | filter_key, filter_values, operator | 根据键值对过滤数据。 |
| 追加或更新 | append_update_data | 添加或更新键值对。 |
| 移除键 | remove_keys_input | 从数据中移除指定的键。 |
| 重命名键 | rename_keys_input | 重命名数据中的键。 |
DataFrame 操作
DataFrame 操作组件对 DataFrame(表格)的行和列执行操作,包括模式更改、记录更改、排序和过滤。
有关所有选项,请参阅 DataFrame 操作参数。
输出是一个新的 DataFrame,包含运行选定操作后修改的数据。
在流程中使用 DataFrame Operations 组件
以下步骤说明如何在流程中配置 DataFrame Operations 组件。
您可以跟随示例进行操作,也可以使用自己的流程。
唯一的要求是,前一个组件必须创建可以传递给 DataFrame Operations 组件的 DataFrame 输出。
-
创建新流程或使用现有流程。
示例:API 响应提取流程
以下示例流程使用五个组件从 API 响应中提取
Data,将其转换为DataFrame,然后使用 DataFrame Operations 组件对表格数据进行进一步处理。 第六个组件 Chat Output 在此示例中是可选的。 它只是为您在 Playground 中查看最终输出提供了一种便捷方式,而不是检查组件日志。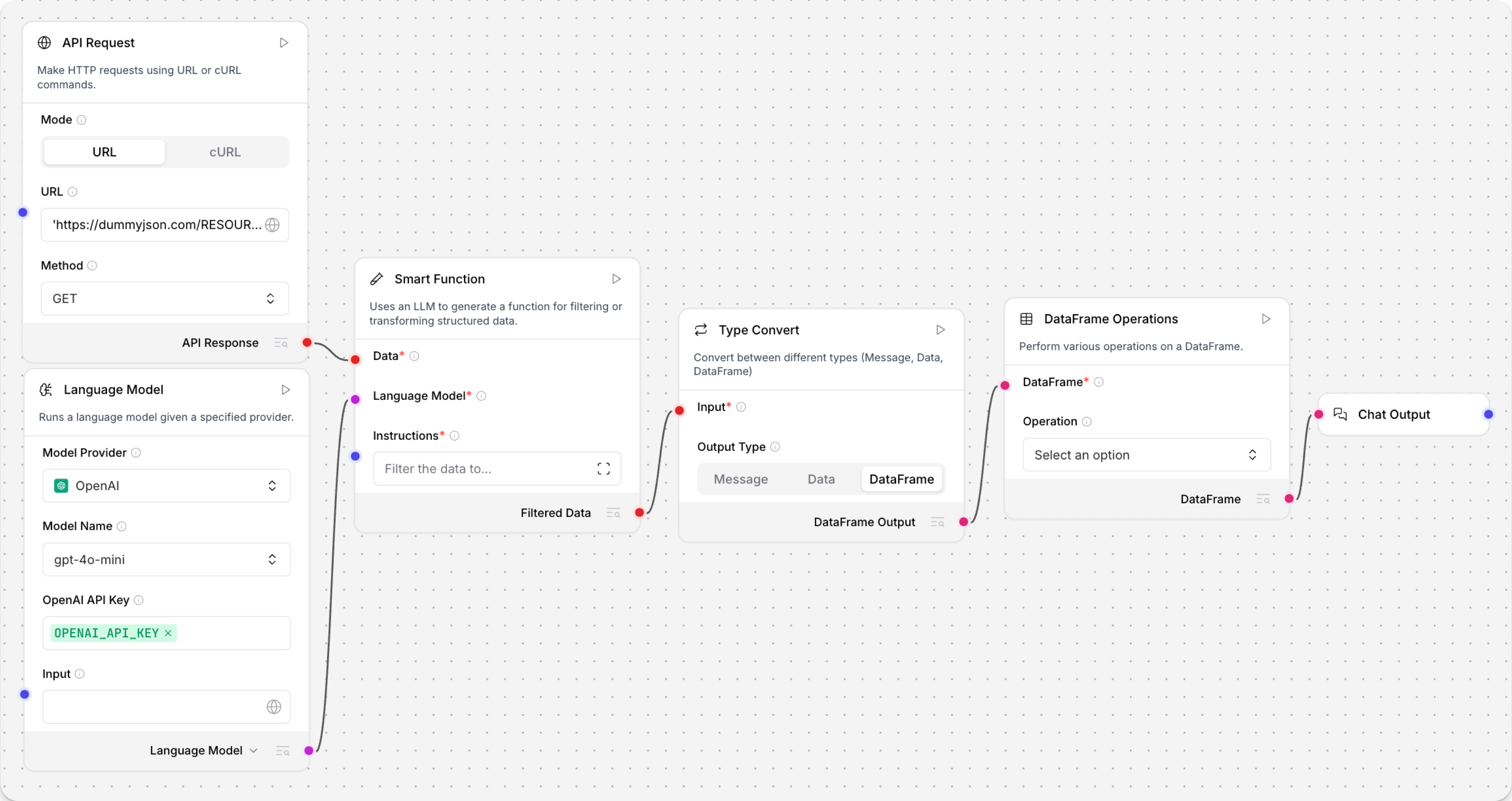
如果您想使用此示例测试 DataFrame Operations 组件,请执行以下操作:
-
创建包含以下组件的流程:
- API Request
- Language Model
- Smart Function
- Type Convert
-
配置 Smart Function 组件 及其依赖项:
- API Request:配置 API Request 组件 以从您选择的端点获取 JSON 数据,然后将 API Response 输出连接到 Smart Function 组件的 Data 输入。
- Language Model:选择您首选的提供商和模型,然后输入有效的 API 密钥。
将输出更改为 Language Model,然后将
LanguageModel输出连接到 Smart Function 组件的 Language Model 输入。 - Smart Function:在 Instructions 字段中,输入自然语言指令以从 API 响应中提取数据。
您的指令取决于响应内容和期望结果。
例如,如果响应包含一个大型
result字段,您可能会提供类似explode the result field out into a Data object的指令。
-
将 Smart Function 组件的
Data输出转换为DataFrame:- 将 Filtered Data 输出连接到 Type Convert 组件的 Data 输入。
- 将 Type Convert 组件的 Output Type 设置为 DataFrame。
现在流程已准备好,您可以添加 DataFrame Operations 组件了。
-
-
将 DataFrame Operations 组件添加到流程中,然后将另一个组件的
DataFrame输出连接到 DataFrame 输入。DataFrame Operations 组件中的所有操作都需要至少一个来自另一个组件的
DataFrame输入。 如果某个组件不产生DataFrame输出,您可以使用另一个组件(如 Type Convert 组件)在数据传递给 DataFrame Operations 组件之前重新格式化数据。 或者,您可以考虑使用专门用于处理原始数据类型的组件,如 Parser 或 Data Operations 组件。如果您正在跟随示例流程进行操作,请将 Type Convert 组件的 DataFrame Output 端口连接到 DataFrame 输入。
-
在 Operations 字段中,选择您要对传入的
DataFrame执行的操作。 例如,Filter 操作根据指定的列和值过滤行。提示您只能选择一个操作。 如果需要对数据执行多个操作,可以将多个 DataFrame Operations 组件链接在一起,以顺序执行每个操作。 对于更复杂的多步操作,如重大的架构更改或透视操作,可以考虑使用由 LLM 驱动的组件,如 Structured Output 或 Smart Function 组件,作为 DataFrame Operations 组件的替代或准备。 :::如果您正在按照示例流程操作,请选择您想要应用于 Smart Function 组件提取的数据的任何操作。 要查看传入的
DataFrame的内容,请在 Type Convert 组件上点击 Run component,然后点击 Inspect output。 如果DataFrame似乎格式不正确,请点击每个上游组件上的 Inspect output 以确定错误发生的位置,然后根据需要修改您的流程配置。 例如,如果 Smart Function 组件没有提取预期的字段,请修改您的指令或验证给定的字段是否存在于 API Response 输出中。 -
配置操作的参数。 具体参数取决于所选操作。 例如,如果您选择 Filter 操作,则必须使用 Column Name、Filter Value 和 Filter Operator 参数定义过滤条件。 有关更多信息,请参阅 DataFrame Operations parameters
-
要测试流程,请在 DataFrame Operations 组件上点击 Run component,然后点击 Inspect output 以查看从 Filter 操作创建的新
DataFrame。如果您想在 Playground 中查看输出,请将 DataFrame Operations 组件的输出连接到 Chat Output 组件,重新运行 DataFrame Operations 组件,然后点击 Playground。
有关另一个示例,请参阅 Conditional looping。
DataFrame 操作参数
大多数 DataFrame 操作 参数都是条件性的,因为它们只适用于特定的操作。
唯一的永久参数是 DataFrame (df),即 DataFrame 输入,以及 操作 (operation),即要对 DataFrame 执行的操作。
一旦您选择了一个操作,该操作的条件参数就会出现在 DataFrame 操作 组件中。
- Add Column
- Drop Column
- Filter
- Head
- Rename Column
- Replace Value
- Select Columns
- Sort
- Tail
- Drop Duplicates
添加列 操作允许您使用常量值向 DataFrame 添加新列。
参数为 新列名 (new_column_name) 和 新列值 (new_column_value)。
删除列 操作允许您从 DataFrame 中删除列,由 列名 (column_name) 指定。
筛选 操作允许您根据指定条件筛选 DataFrame。
输出是一个仅包含匹配筛选条件的行的 DataFrame。
提供以下参数:
- 列名 (
column_name):要筛选的列的名称。 - 筛选值 (
filter_value):要筛选的值。 - 筛选操作符 (
filter_operator):用于筛选的操作符,包括equals(默认)、not equals、contains、starts with、ends with、greater than或less than之一。
头部 操作允许您获取 DataFrame 的前 n 行,其中 n 在 行数 (num_rows) 中设置。
默�认值为 5。
输出是一个仅包含所选行的 DataFrame。
重命名列 操作允许您重命名 DataFrame 中的现有列。
参数为 列名 (column_name),即当前名称,和 新列名 (new_column_name)。
替换值 操作允许您替换 DataFrame 特定列中的值。
此操作将目标值替换为新值。
在新 DataFrame 输出中,所有匹配目标值的单元格都会被替换为新值。
提供以下参数:
- 列名 (
column_name):要修改的列的名称。 - 要替换的值 (
replace_value):您想要替换的值。 - 替换值 (
replacement_value):要使用的新值。
选择列 操作允许您从 DataFrame 中选择一个或多个特定列。
在 要选择的列 (columns_to_select) 中提供列名列表。
在可视化编辑器中,点击 添加更多 来添加多个字段,然后在每个字段中输入一个列名。
输出是一个仅包含指定列的 DataFrame。
排序 操作允许您按特定列对 DataFrame 进行升序或降序排序。
提供以下参数:
- 列名 (
column_name):要排序的列的名称。 - 升序排序 (
ascending):是否按升序或降序排序。如果启用(true),则按升序排序;如果禁用(false),则按降序排序。默认值:启用(true)
尾部 操作允许您获取 DataFrame 的最后 n 行,其中 n 在 行数 (num_rows) 中设置。
默认值为 5。
输出是一个仅包含所选行的 DataFrame。
删除重复项 操作通过识别单个列中的所有重复值来从 DataFrame 中删除行。
唯一的参数是 列名 (column_name)。
当流程运行时,给定列中具有重复值的所有行都会被删除。
输出是一个包含原始 DataFrame 中所有列但仅包含非重复值的行的 DataFrame。
LLM路由器
LLM路由器组件根据OpenRouter模型规范将请求路由到最合适的LLM。
要在工作流中使用此组件,您需要将多个语言模型组件连接到LLM路由器组件。 其中一个模型是判断LLM,它分析输入消息以理解评估上下文,从其他附加的LLM中选择最合适的模型,然后将输入路由到所选模型。 所选模型处理输入,然后返回生成的响应。
以下示例工作流包含三个语言模型组件。 一个是判断LLM,另外两个在用于请求路由的LLM池中��。 聊天输入和聊天输出组件创建了一个无缝的聊天交互,您可以在其中发送消息并接收响应,而无需用户了解底层路由。
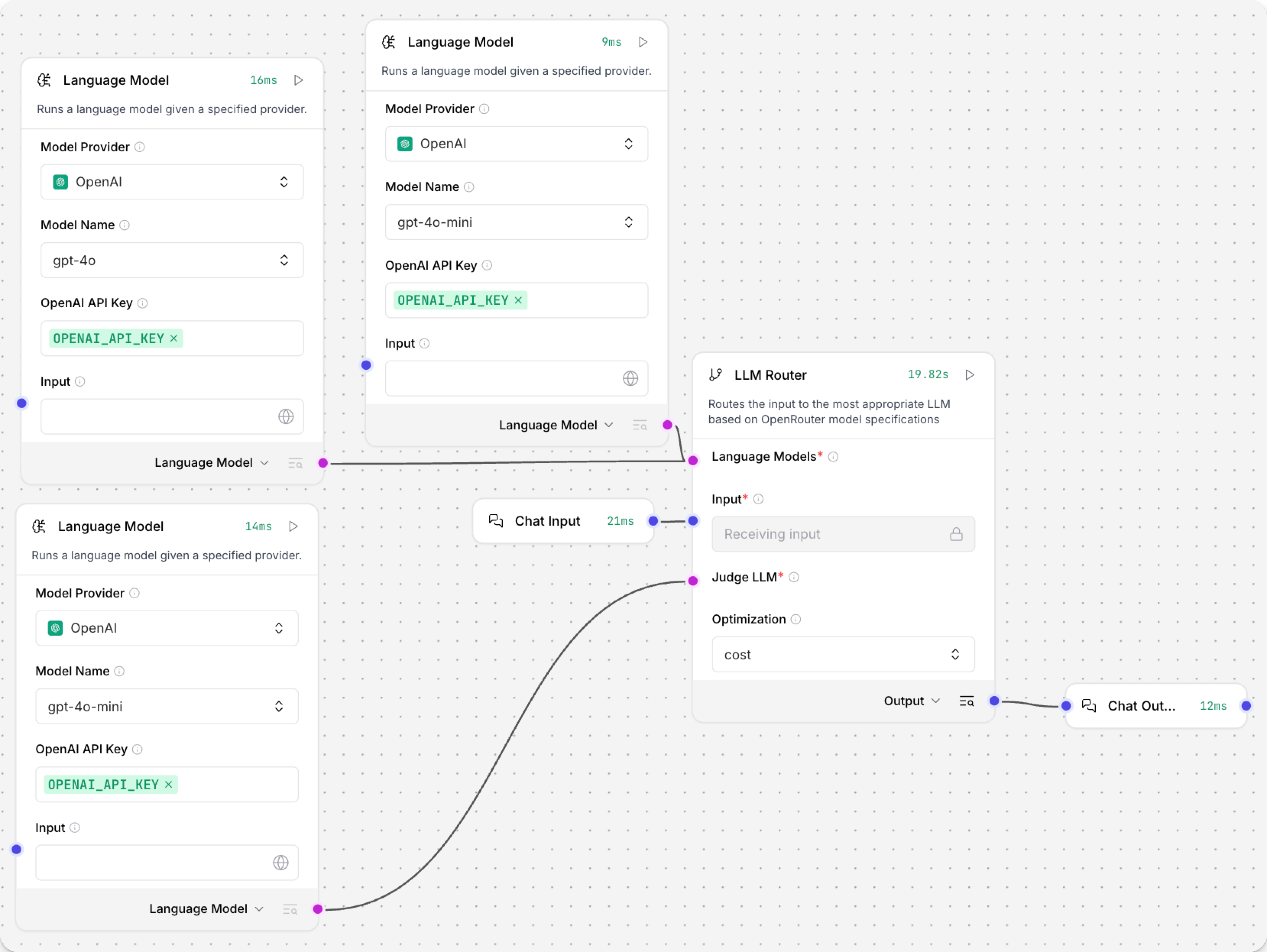
LLM路由器参数
在可视化编辑器中,部分参数默认情况下是隐藏的。 您可以通过组件的头部菜单中的 控件 来修改所有参数。
| 名称 | 显示名称 | 信息 |
|---|---|---|
models | 语言模型 | 输入参数。连接多个语言模型组件的LanguageModel输出,以创建模型池。judge_llm在路由请求时从此池中选择模型。如果模型选择或路由出现问题,您连接的第一个模型将是默认模型。 |
input_value | 输入 | �输入参数。要路由到判断LLM所选模型的查询。 |
judge_llm | 判断LLM | 输入参数。连接来自_一个_语言模型组件的LanguageModel输出,作为请求路由的判断LLM。 |
optimization | 优化 | 输入参数。设置判断LLM选择模型的偏好特性。选项包括quality(最高响应质量)、speed(最快响应时间)、cost(最具成本效益的模型)或balanced(质量、速度和成本的权重相等)。默认值:balanced |
use_openrouter_specs | 使用OpenRouter规范 | 输入参数。是否从OpenRouter API获取模型规范。如果为false,则只向判断LLM提供模型名称。默认值:已启用(true) |
timeout | API超时 | 输入参数。设置路由器发出的API请求的超时时间(秒)。默认值:10 |
fallback_to_first | 回退到第一个模型 | 输入参数。如果路由无法到达所选模型,是否使用models中的第一个LLM作为备用。默认值:已启用(true) |
LLM路由器输出
LLM路由器组件提供三种输出选项。 您可以在组件的输出端口附近设置所需的输出类型。
-
输出:包含所选LLM生成的对原始查询的响应的
Message。 用于常规聊天交互。 -
所选模型信息:包含所选模型信息的
Data对象,如名称和版本。 -
路由决策:包含判断模型选择特定模型的推理的
Message,包括输入查询长度和考虑的模型数量。 例如:_10模型选择决策:_10- 所选模型索引:0_10- 所选Langflow模型名称:gpt-4o-mini_10- 所选API模型ID(如果已解析):openai/gpt-4o-mini_10- 优化偏好:成本_10- 输入查询长度:27个字符(约5个token)_10- 考虑的模型数量:2_10- 规范来源:OpenRouter API如果您认为判断模型没有选择最佳模型,这对于调试很有用。
解析器
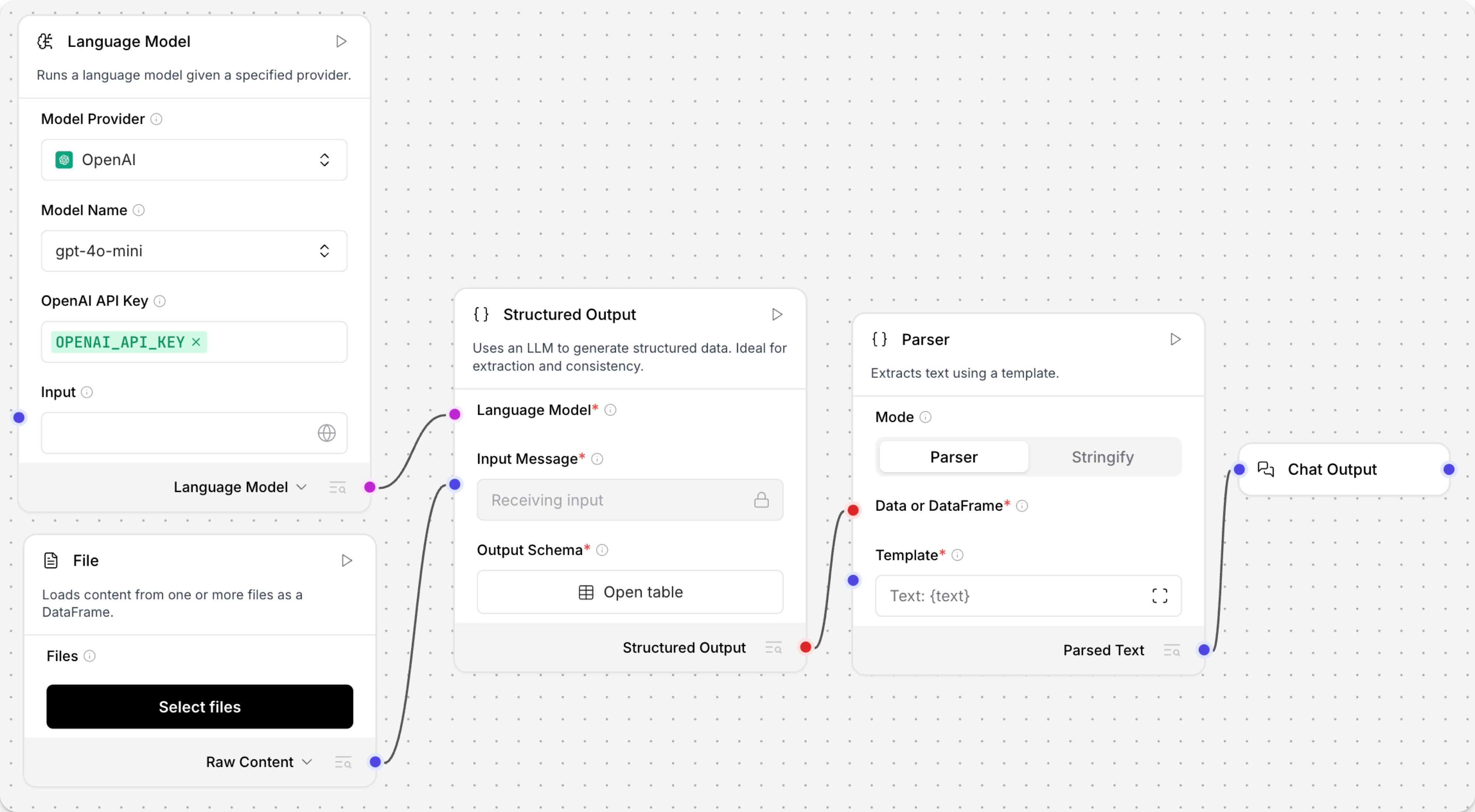
解析器组件使用模板或直接字符串化从结构化数据(DataFrame或Data)中提取文本。
输出是包含已解析文本的Message。
这是一个多功能组件,用于在工作流中进行数据提取和操作。 有关工作流中解析器组件的示例,请参见以下内容:
- 批量运行组件示例
- 结构化输出组件示例
- 财务报告解析器模板
- 使用webhook触发工作流
- 创建向量RAG聊天机器人
解析模式
Parser 组件有两种模式:Parser 和 Stringify。
- Parser(模板)模式
- Stringify 模式
在 Parser 模式下,您创建一个文本输出模板,可以包含字面字符串和用于提取键的变量。
使用花括号在模板中的任何位置定义变量。
变量必须与 DataFrame 或 Data 输入中的键匹配,例如列名。
例如,{name} 提取 name 键的值。
有关 DataFrame 和 Data 对象的内容和结构的更多信息,请参阅 Langflow 数据类型。
当流程运行时,Parser 组件会遍历输入,为每个解析的项目生成一个 Message。
例如,解析 DataFrame 会为每一行创建一个 Message,填充该行的唯一值。
员工摘要模板
此示例模板将员工数据提取为关于员工入职日期和当前职位的自然语言摘要:
_10{employee_first_name} {employee_last_name} was hired on {start_date}._10Their current position is {job_title} ({grade}).
生成的 Message 输出将变量替换为相应的提取值。
例如:
_10Renlo Kai was hired on 11-July-2017._10Their current position is Software Engineer (Principal).
员工档案模板
此示例模板使用 Markdown 语法和提取的员工数据来创建员工档案:
_10# Employee Profile_10## Personal Information_10- **Name:** {name}_10- **ID:** {id}_10- **Email:** {email}
当流程运行时,Parser 组件会遍历 DataFrame 的每一行,用适当的提取值填充模板的变量。
每行的结果文本会作为 Message 输出。
Parser 模式下可用的参数如下。
在可视化编辑器中,部分参数默认情况下是隐藏的。 您可以通过组件的头部菜单中的 控件 来修改所有参数。
| Name | Display Name | Info |
|---|---|---|
| input_data | Data or DataFrame | 输入参数。要解析的 Data 或 DataFrame 输入。 |
| pattern | Template | 输入参数。使用纯文本和键变量({KEY_NAME})的格式化模板。更多信息请参见前面的示例。 |
| sep | Separator | 输入参数。定义行或行分隔符的字符串。默认值:\n(换行符)。 |
| clean_data | Clean Data | 是否移除 DataFrame 或 Data 输入中每个单元格或键的空行和空行。默认值:已启用(true) |
使用 Stringify 模式将整个输入直接转换为文本。 此模式不支持模板或键选择。
Stringify 模式下可用的参数如下。
在可视化编辑器中,部分参数默认情况下是隐藏的。 您可以通过组件的头部菜单中的 控件 来修改所有参数。
| Name | Display Name | Info |
|---|---|---|
| input_data | Data or DataFrame | 输入参数。要解析的 Data 或 DataFrame 输入。 |
| sep | Separator | 输入参数。定义行或行分隔符的字符串。默认值:\n(换行符)。 |
| clean_data | Clean Data | 是否移除 DataFrame 或 Data 输入中每个单元格或键的空行和空行。默认值:已启用(true) |
测试和排查解析文本
要测试 Parser 组件,点击 运行组件,然后点击 检查输出 来查看包含解析文本的 Message 输出。
如果想在 Playground 中查看输出,也可以连接一个 Chat Output 组件。
如果来自 Parser 组件的 Message 输出为空或包含意外值,可能是输入与解析模式之间存在映射错误,输入值为空,或者输入不适合进行纯文本提取。
例如,假设您使用以下模板来解析 DataFrame:
_10{employee_first_name} {employee_last_name} is a {job_title} ({grade}).
解析 employee_first_name 为空且 grade 为 null 的行时,可能会产生以下 Message:
_10 Smith is a Software Engineer (null).
要排查缺失或意外的值,您可以执行以下操作:
-
确保模板中的变量映射到传入的
Data或DataFrame中的键。 要查看直接传递给 Parser 组件的数据,点击向 Parser 组件发送数据的组件上的 检查输出。 -
检查源数据中是否存在缺失或不正确的值。 您可以通过几种方式解决这些不一致问题:
- 直接修正源数据。
- 在将数据传递给 Parser 组件之前,使��用其他组件来修改或过滤异常值。 根据您的目标,您可以使用许多组件来完成此操作,例如 Data Operations、Structured Output 和 Smart Function 组件。
- 启用 Parser 组件的 Clean Data 参数以跳过空行或空行。
Python 解释器
此组件允许您执行带有导入包的 Python 代码。
Python 解释器 组件只能导入已安装在您的 Langflow 环境中的包。
如果在使用包时遇到 ImportError,您需要先安装它。
要安装自定义包,请参阅 安装自定义依赖。
在工作流中使用 Python 解释器
- 要在工作流中使用此组件,在 全局导入 字段中,添加您要导入的包作为逗号分隔的列表,例如
math,pandas。 至少需要一个导入。 - 在 Python 代码 字段中,输入您要执行的 Python 代码。使用
print()来查看输出。 - 可选:启用 工具模式,然后将 Python 解释器 组件连接到 Agent 组件作为工具。
例如,将 Python 解释器 组件和 计算器组件 连接为 Agent 组件的工具,然后测试它如何选择不同的工具来解决数学问题。
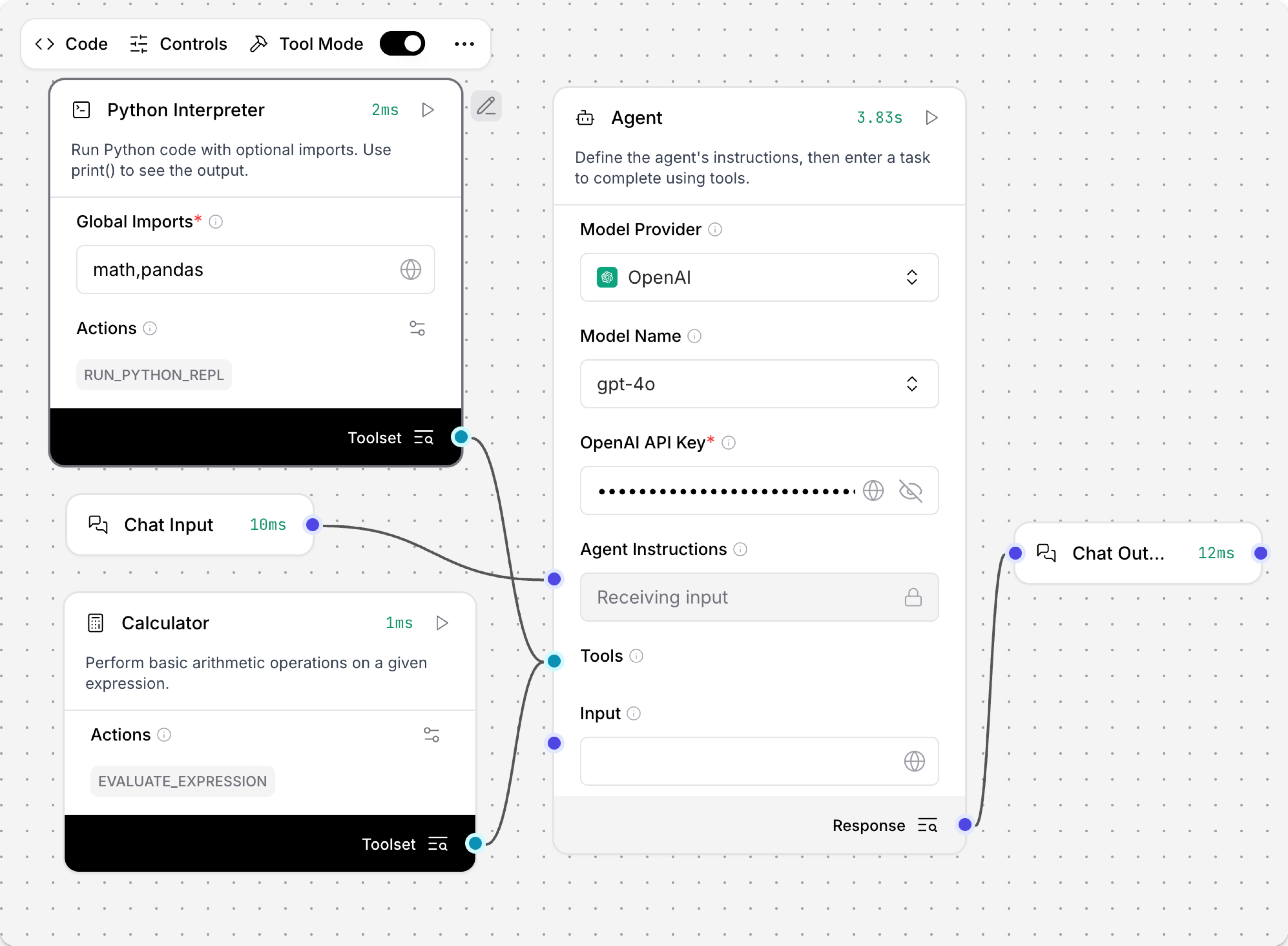
- 向代理提出一个简单的数学问题。
计算器 工具可以执行加法、减法、乘法、除法或指数运算。
代理执行
evaluate_expression工具来正确回答问题。
结果:
_10执行了 evaluate_expression_10输入:_10{_10 "expression": "2+5"_10}_10输出:_10{_10 "result": "7"_10}
- 向代理提供完整的 Python 代码。
此示例使用导入的
pandas包创建一个 Pandas DataFrame 表,并返回均方根。
_12import pandas as pd_12import math_12_12# 创建一个简单的 DataFrame_12df = pd.DataFrame({_12 'numbers': [1, 2, 3, 4, 5],_12 'squares': [x**2 for x in range(1, 6)]_12})_12_12# 计算均方根_12result = math.sqrt(df['squares'].mean())_12print(f"均方根: {result}")
代理正确选择 run_python_repl 工具来解决问题。
结果:
_12执行了 run_python_repl_12_12输入:_12_12{_12 "python_code": "import pandas as pd\nimport math\n\n# 创建一个简单的 DataFrame\ndf = pd.DataFrame({\n 'numbers': [1, 2, 3, 4, 5],\n 'squares': [x**2 for x in range(1, 6)]\n})\n\n# 计算均方根\nresult = math.sqrt(df['squares'].mean())\nprint(f\"均方根: {result}\")"_12}_12输出:_12_12{_12 "result": "均方根: 3.3166247903554"_12}
如果您在聊天中没有包含包导入,代理仍然可以使用 pd.DataFrame 创建表,因为 pandas 包已通过 Python 解释器 组件在 全局导入 字段中全局导入。
Python 解释器参数
| Name | Type | Description |
|---|---|---|
| global_imports | String | 输入参数。要全局导入的模块的逗号分隔列表,例如 math,pandas,numpy。 |
| python_code | Code | 输入参数。要执行的 Python 代码。只能使用全局导入中指定的模块。 |
| results | Data | 输出参数。执行 Python 代码的输出,包括任何打印的结果或错误。 |
保存文件
保存文件 组件创建一个包含由其他组件生成的数据的文件。 支持多种文件格式,您可以将文件存储在 Langflow 存储 或本地文件系统中。
要配置 保存文件 组件并在流程中使用它,请执行以下操作:
-
将另一个组件的
DataFrame、Data或Message输出连接到 保存文件 组件的 输入 端口。如果您想创建多个文件、以不同的文件格式保存数据或将文件保存到多个位置,可以将相同的输出连接到多个 保存文件 组件。
-
在 文件名 中输入文件名和可选路径。
文件名 参数控制文件的保存位置。 它可以包含文件名或完整的文件路径:
-
默认位置:如果您只提供文件名,则文件将存储在 Langflow 数据目录中。例如,在 macOS 上为
~/Library/Caches/langflow/data。 -
子目录:要将文件存储在子目录中,请将路径添加到 文件名 参数中。 如果给定的子目录不存在,Langflow 会自动创建它。 例如,
files/my_file会在/data/files中创建my_file,如果files子目录不存在,则会创建它。 -
绝对或相对路径:要将文件存储在环境或本地文件存储的其他位置,请提供所需位置的绝对或相对路径。 例如,
~/Desktop/my_file将my_file保存到桌面。
不要在文件名中包含扩展名。 如果包含,扩展名将被视为文件名的一部分;它对 文件格式 参数没有影响。
-
-
在 组件的头部菜单 中,点击 控制,选择所需的文件格式,然后点击 关闭。
可用的 文件格式 选项取决于输入数据类型:
-
DataFrame可以保存为 CSV(默认)、Excel(需要openpyxl自定义依赖)、JSON(备用默认)或 Markdown。 -
Data可以保存为 CSV、Excel(需要openpyxl自定义依赖)、JSON(默认)或 Markdown。 -
Message可以保存为 TXT、JSON(默认)或 Markdown。
允许覆盖如果您有多个 保存文件 组件,在一个或多个流程中,具有相同的文件名、路径和扩展名,则文件仅包含最近运行的数据。 如果已存在匹配的文件,Langflow 不会阻止覆盖。 为避免意外覆盖,请使用唯一的文件名和路径。
-
-
要测试 保存文件 组件,点击 运行组件,然后点击 检查输出 以获取文件保存的文件路径。
组件的文本输出是一个包含原始数据类型、文件名和扩展名以及基于 文件名 参数的文件绝对路径的
Message。 例如:_10DataFrame 成功保存为 'my_file.csv' 到 /Users/user.name/Library/Caches/langflow/data/my_file.csv如果 文件名 包含子目录或其他非默认路径,这会在
Message输出中反映出来。 例如,文件名为~/Desktop/my_file的 CSV 文件可能会产生以下输出:_10DataFrame 成功保存为 '/Users/user.name/Desktop/my_file.csv' 到 /Users/user.name/Desktop/my_file.csv -
可选:如果您想在流程中使用保存的文件,必须使用 API 调用或其他组件从给定的文件路径中检索文件。
智能函数
在 Langflow 1.5 版本中,此组件从 Lambda Filter 重命名为 Smart Function。
智能函数 组件使用 LLM 生成 Lambda 函数,根据自然语言指令来过滤或转换结构化数据。
您必须将此组件连接到 Language Model 组件,该组件用于根据您在 Instructions 参数中提供的自然语言指令生成函数。
LLM 针对数据输入运行函数,然后将结果输出为 Data。
提供简明清晰的指令,重点关注期望的结果或具体操作,例如 Filter the data to only include items where the 'status' is 'active'。
最好使用一句话或少于一句,因为句末标点(如句点)可能导致错误或意外行为。
如果您需要提供更多与 Lambda 函数不直接相关的详细指令,可以在 Language Model 组件的 Input 字段中输入,或通过 Prompt Template 组件输入。
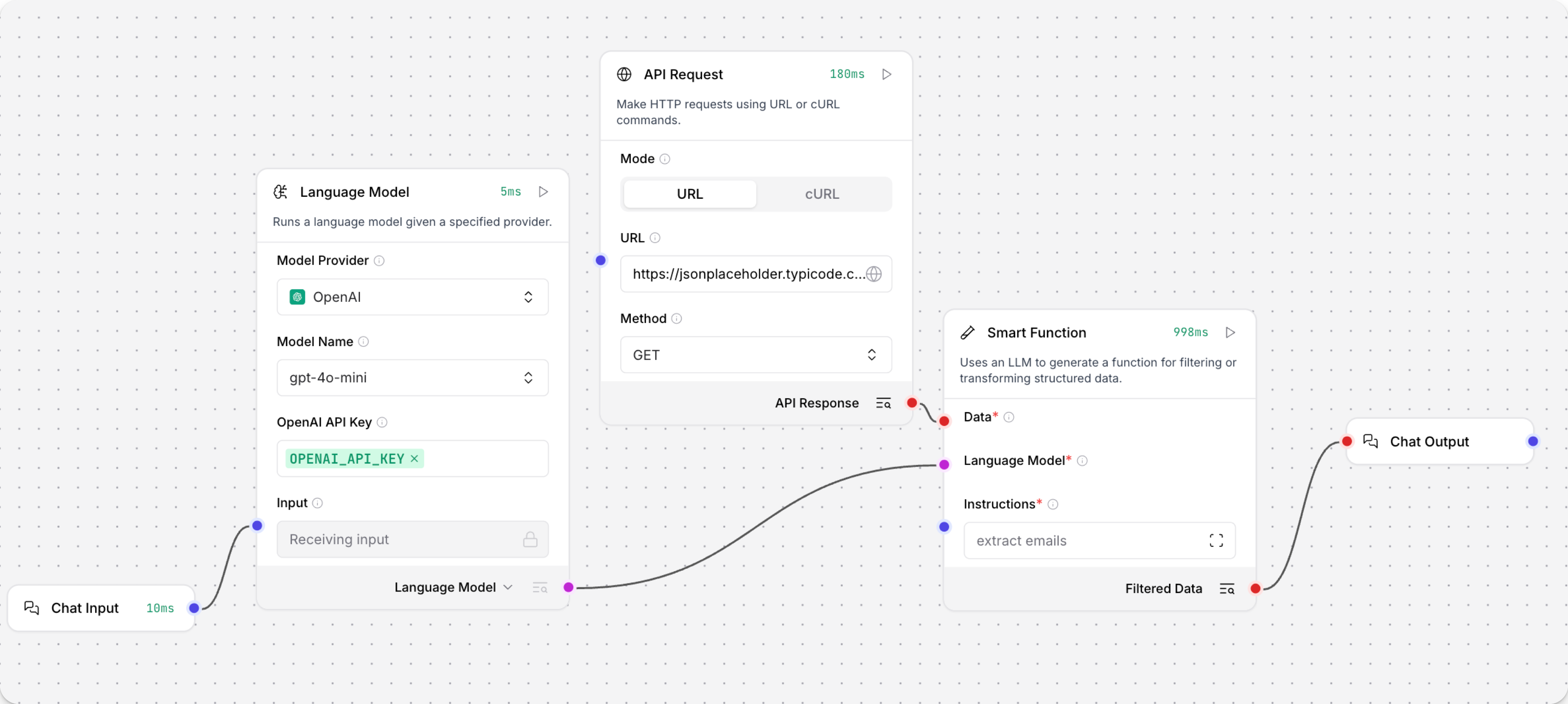
以下示例使用 API Request 端点将来自 https://jsonplaceholder.typicode.com/users 端点的 JSON 数据传递给 Smart Function 组件。
然后,Smart Function 组件将数据和指令 extract emails 传递给连接的 Language Model 组件。
接着,LLM 生成一个从 JSON 数据中提取电子邮件地址的过滤函数,将过滤后的数据作为聊天输出返回。
智能函数参数
在可视化编辑器中,部分参数默认情况下是隐藏的。 您可以通过组件的头部菜单中的 控件 来修改所有参数。
| 名称 | 显�示名称 | 信息 |
|---|---|---|
| data | 数据 | 输入参数。使用 Lambda 函数过滤或转换的结构化数据。 |
| llm | 语言模型 | 输入参数。连接来自 Language Model 组件的 LanguageModel 输出。 |
| filter_instruction | 指令 | 输入参数。如何过滤或转换数据的自然语言指令。LLM 使用这些指令创建 Lambda 函数。 |
| sample_size | 样本大小 | 输入参数。对于大型数据集,从数据集头部和尾部采样的字符数。仅当数据集达到或超过 max_size 时应用。默认值:1000。 |
| max_size | 最大大小 | 输入参数。数据集被视为大型数据集的字符数,这将触发按 sample_size 值进行采样。默认值:30000。 |
分割文本
分割文本 组件根据块大小和分隔符等参数将数据分割成块。 它通常用于将数据分块以便进行标记化和嵌入到向量数据库中。 有关示例,请参阅 在流程中使用向量存储组件、在流程中使用嵌入模型组件 和 创建向量 RAG 聊天机器人。
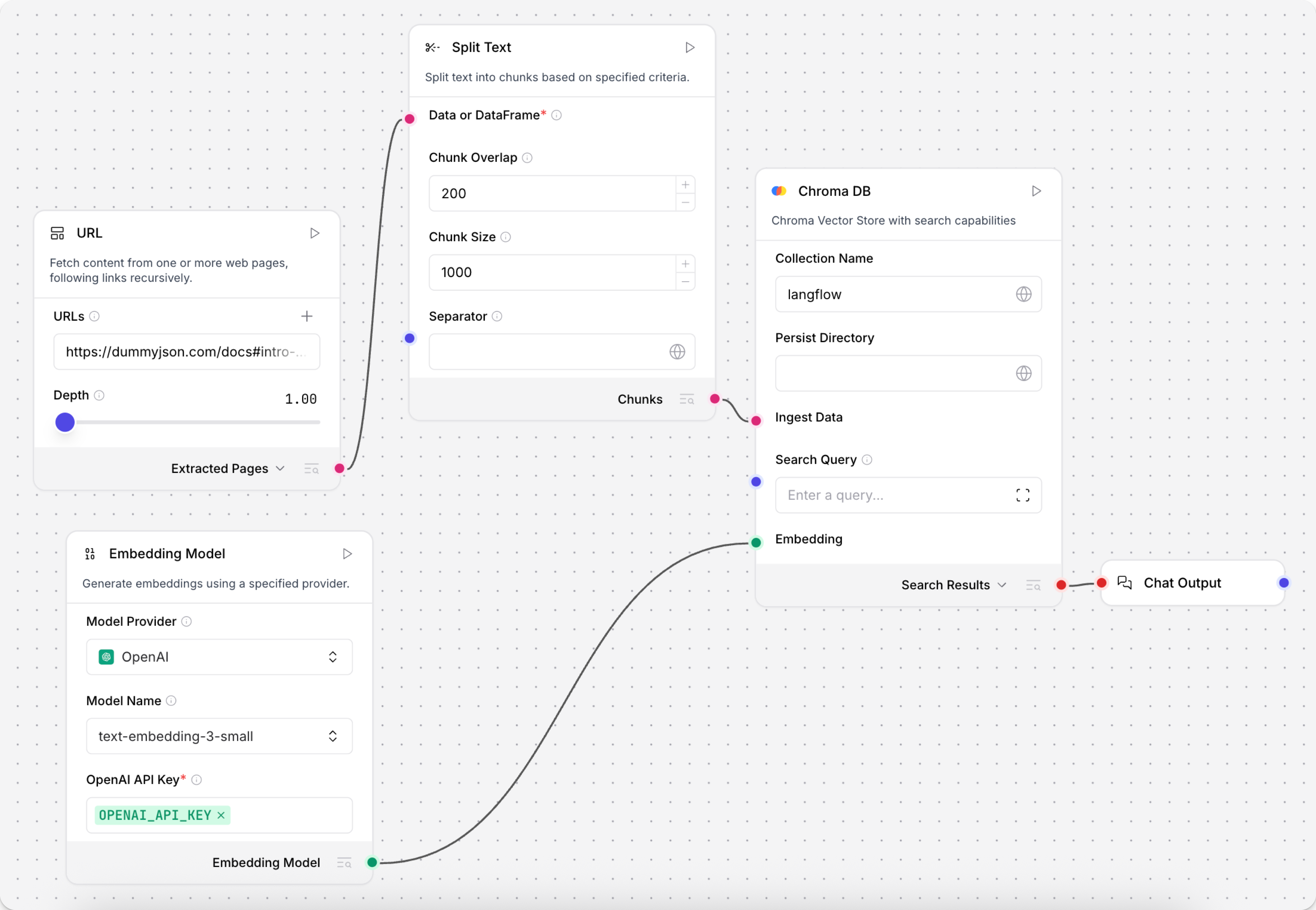
该组件接受 Message、Data ��或 DataFrame,然后输出 Chunks 或 DataFrame。
Chunks 输出返回包含各个文本块的 Data 对象列表。
DataFrame 输出将块列表作为结构化的 DataFrame 返回,并包含额外的 text 和 metadata 列。
分割文本参数
分割文本 组件的参数控制文本如何分割成块,特别是 chunk_size、chunk_overlap 和 separator 参数。
要测试分块行为,请添加一个包含一些示例数据的 文本输入 或 文件 组件进行分块,点击 分割文本 组件上的 运行组件,然后点击 检查输出 来查看块列表及其元数据。文本 列包含根据您的分块设置创建的实际文本块。 如果分块结果不符合预期,请调整参数,重新运行组件,然后检查新的输出。
在可视��化编辑器中,部分参数默认情况下是隐藏的。 您可以通过组件的头部菜单中的 控件 来修改所有参数。
| Name | Display Name | Info |
|---|---|---|
| data_inputs | 输入 | 输入参数。要分割的数据。输入必须为 Message、Data 或 DataFrame 格式。 |
| chunk_overlap | 块重叠 | 输入参数。块之间重叠的字符数。这有助于在块之间保持上下文。当遇到分隔符时,重叠会在分隔符处应用,以便后续块包含前一个块的最后 n 个字符。默认值:200。 |
| chunk_size | 块大小 | 输入参数。分割后每个块的目标长度。数据首先按分隔符分割,然后小于 chunk_size 的块会合并到此限制。然而,如果初始的分隔符分割产生任何大于 chunk_size 的块,这些块既不会被进一步细分,也不会与任何较小的块合并;这些块将按原样输出,即使它们超过了 chunk_size。默认值:1000。有关重要注意事项,请参阅 由于块大小导致的标记化错误。 |
| separator | 分隔符 | 输入参数。定义要分割的字符的字符��串,例如 \n 用于分割换行符,\n\n 用于分割段落,或 }, 用于分割 JSON 对象的结尾。您可以直接提供分隔符字符串,或从另一个组件将分隔符字符串作为 Message 输入传递。 |
| text_key | 文本键 | 输入参数。用于从输入中提取并分割的文本列的键。默认值:text。 |
| keep_separator | 保留分隔符 | 输入参数。选择如何处理输出块中的分隔符。如果为 False,则从输出块中省略分隔符。选项包括 False(移除分隔符)、True(在块中保留分隔符,不优先考虑位置)、Start(将分隔符放在块的开头)或 End(将分隔符放在块的结尾)。默认值:False。 |
由于块大小导致的标记化错误
当将 分割文本 与嵌入模型一起使用时(特别是 NVIDIA 模型如 nvidia/nv-embed-v1),即使模型支持更大的标记限制,您可能也需要使用更小的块大小(500 或更少)。
分割文本 组件并不总是强制执行您设置的确切块大小,单个块可能会超过您指定的限制。
如果遇到标记化错误,请通过减小块大小、更改重叠长度或使用更常见的分隔符来修改您的文本分割策略。 然后,通过运行流程并检查组件输出来测试您的配置。
其他文本分割器
请参阅 LangChain 文本分割器组件。
结构化输出
结构化输出 组件使用 LLM 将任何输入转换为结构化数据(Data 或 DataFrame),使用自然语言格式化指令和输出模式定义。
例如,您可以从文档中提取特定细节,如电子邮件或科学论文。
在流程中使用结构化输出组件
要在流程中使用结构化输出组件,请执行以下操作:
-
提供输入消息,这是您想要从中提取结构化数据的源材料。 这可以来自几乎任何组件,但通常是聊天输入、文件或其他提供某种非结构化或半结构化输入的组件。
提示并非所有源材料都需要成为结构化输出。 结构化输出组件的强大之处在于,您可以指定要提取的信息,即使这些数据没有明确标记或不是精确的关键字匹配。 然后,LLM可以使用您的指令来分析源材料,提取相关数据,并根据您的规范进行格式化。 任何不相关的源材料都不会包含在结构化输出中。
-
定义格式说明和输出模式,以指定要从源材料中提取的数据以及如何在最终的
Data或DataFrame输出中对其进行结构化。这些说明是一个提示,告诉LLM要提取什么数据、如何格式化、如何处理异常以及任何其他与准备结构化数据相关的说明。
模式是一个表格,定义了字段(键)和数据类型,用于将由LLM提取的数据组织成结构化的
Data或DataFrame对象。 有关更多信息,请参见输出模式选项 -
附加一个设置为发出
LanguageModel输出的语言模型组件。LLM使用结构化输出组件中的输入消息和格式说明从输入文本中提取特定的数据片段。 输出模式应用于模型的响应,以生成最终的
Data或DataFrame结构化对象。 -
可选:通常,结构化输出会传递给下游组件,这些组件使用提取的数据进行其他处理,例如解析器或数据操作组件。
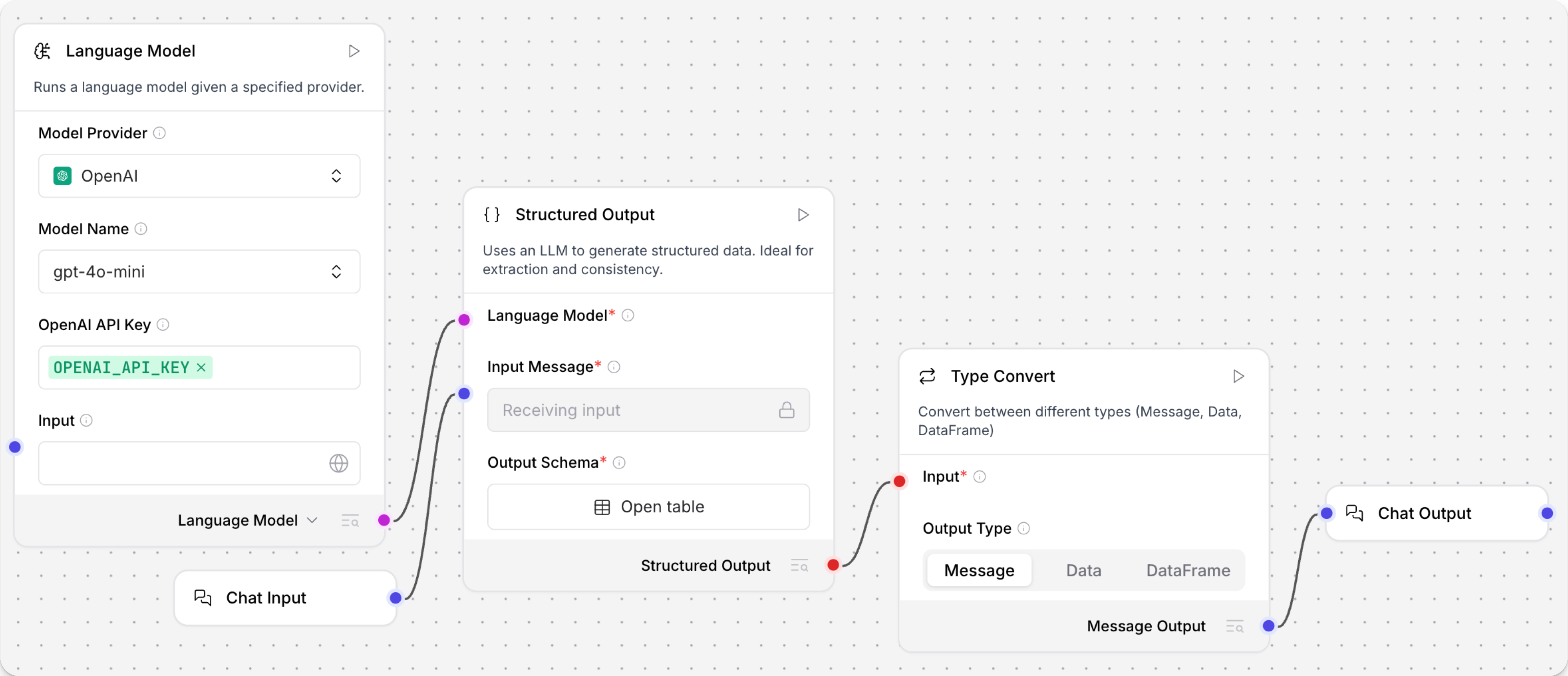
结构化输出示例:财务报告解析器模板
财务报告解析器模板展示了如何使用结构化输出组件从非结构化文本中提取结构化数据的示例。
该模板的结构化输出组件具有以下配置:
-
输入消息来自一个聊天输入组件,该组件预加载了示例财务报告的引用
-
格式说明如下:
_10You are an AI that extracts structured JSON objects from unstructured text._10Use a predefined schema with expected types (str, int, float, bool, dict)._10Extract ALL relevant instances that match the schema - if multiple patterns exist, capture them all._10Fill missing or ambiguous values with defaults: null for missing values._10Remove exact duplicates but keep variations that have different field values._10Always return valid JSON in the expected format, never throw errors._10If multiple objects can be extracted, return them all in the structured format. -
输出模式包含
EBITDA、NET_INCOME和GROSS_PROFIT的键。
结构化的Data对象被传递给一个解析器组件,该组件通过将模式键映射到解析模板中的变量来生成文本字符串:
_10EBITDA: {EBITDA} , Net Income: {NET_INCOME} , GROSS_PROFIT: {GROSS_PROFIT}
当打印到Playground时,生成的Message会将变量替换为结构化输出组件提取的实际值。例如:
_10EBITDA: 900 million , Net Income: 500 million , GROSS_PROFIT: 1.2 billion
结构化输出参数
在可视化编辑器中,部分参数默认情况下是隐藏的。 您可以通过组件的头部��菜单中的 控件 来修改所有参数。
| 名称 | 类型 | 描述 |
|---|---|---|
语言模型 (llm) | LanguageModel | 输入参数。来自语言模型组件的LanguageModel输出,用于定义要用来分析、提取和准备结构化输出的LLM。 |
输入消息 (input_value) | 字符串 | 输入参数。包含用于提取的源材料的输入消息。 |
格式说明 (system_prompt) | 字符串 | 输入参数。向语言模型提供的用于提取和格式化输出的说明。 |
架构名称 (schema_name) | 字符串 | 输入参数。输出架构的可选标题。 |
输出架构 (output_schema) | 表格 | 输入参数。描述所需结构化输出架构的表格,最终决定Data或DataFrame输出的内容。请参阅输出架构选项。 |
结构化输出 (structured_output) | Data或DataFrame | 输出参数。组件产生的最终结构化输出。在组件的输出端口附近,您可以选择��输出数据类型为结构化输出数据或结构化输出DataFrame。输出的具体内容和结构取决于输入参数。 |
输出架构选项
在LLM从输入消息和格式说明中提取相关数据后,数据会根据输出架构进行组织。
该架构是一个表格,定义了来自结构化输出组件的最终Data或DataFrame输出的字段(键)和数据类型。
默认架构是一个单独的field字符串。
要向架构添加键,点击添加新行,然后编辑每一列来定义架构:
-
名称:输出字段的名称。通常是您想要提取值的特定键。
您可以在下游组件中将这些键作为变量引用,例如解析器组件的模板。 例如,架构键
NET_INCOME可以通过变量{NET_INCOME}进行引用。 -
描述:关于字段内容和用途的可选元数据描述。
-
类型:字段中存储值的数据类型。 支持的数据类型有
str(默认)、int、float、bool和dict。 -
作为列表:如果您希望字段包含值列表而不是单个值,请启用此设置。
对于简单的架构,您可能只提取几个string或int字段。
对于包含列表和字典的更复杂架构,参考Langflow数据类型中描述的Data和DataFrame结构和属性可能会有所帮助。
您也可以输出一个初步的Data或DataFrame,然后使用下游组件进行进一步处理,例如数据操作组件。
类型转换
类型转换组件将数据从一种类型转换为另一种类型。
它支持Data、DataFrame和Message数据类型。
- Data
- DataFrame
- Message
Data对象是一个结构化对象,包含一个主要的text键和其他键值对:
_10"data": {_10 "text": "用户档案",_10 "name": "Charlie Lastname",_10 "age": 28,_10 "email": "[email protected]"_10},
与组件的data字典相关联的更大上下文还会标识哪个键是主要的text_key,如果未指定主键,它可以提供一个可选的默认值。
例如:
_10{_10 "text_key": "text",_10 "data": {_10 "text": "用户档案",_10 "name": "Charlie Lastname",_10 "age": 28,_10 "email": "[email protected]"_10 },_10 "default_value": ""_10}
DataFrame是一个表示具有行和列的表格数据结构的数组。
它由字典对象列表(数组)组成,其中每个字典代表一行。
字典中的每个键对应一个列名。
例如,下面的DataFrame包含两行,分别有name、age和email列:
_12[_12 {_12 "name": "Charlie Lastname",_12 "age": 28,_12 "email": "[email protected]"_12 },_12 {_12 "name": "Bobby Othername",_12 "age": 25,_12 "email": "[email protected]"_12 }_12]
Message主要用于传递text字符串,例如"姓名:Charlie Lastname,年龄:28,邮箱:[email protected]"。
但是,整个Message对象可以包含关于消息的元数据,特别是在用作聊天输入或输出时。
有关更多信息,请参阅Langflow数据类型。
在流程中使用类型转换组件
类型转换组件通常用于将数据转换为下游组件所需的格式。
例如,如果一个组件输出Message,但下游组件需要Data,则可以使用类型转换组�件将Message重新格式化为Data,然后再传递给下游组件。
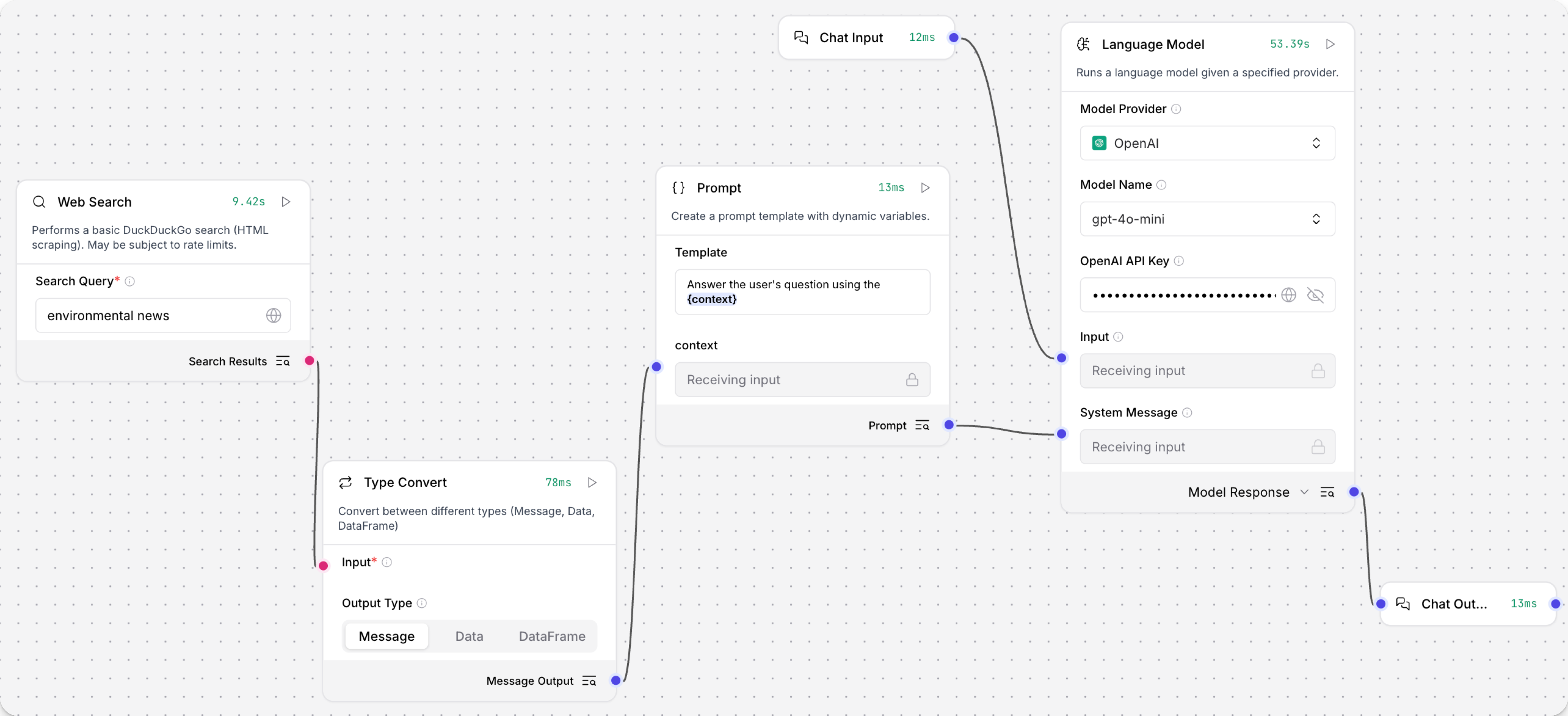
以下示例使用类型转换组件将网络搜索组件输出的DataFrame转换为Message数据,作为LLM的文本输入传递:
-
基于基础提示模板创建流程。
-
向流程中添加网络搜索组件,然后输入搜索查询,例如
environmental news。 -
在提示模板组件中,将模板字段的内容替换为以下文本:
_10使用{context}回答用户的问题花括号定义了一个提示变量,它将成为提示模板组件上的输入字段。 在此示例中,您将使用context字段将搜索结果传递到模板中,如后续步骤所述。
-
向流程中添加类型转换组件,然后将输出类型设置为消息。
由于网络搜索组件的
DataFrame输出与context变量的Message输入不兼容,您必须使用类型转换组件将DataFrame更改为Message,以便将搜索结果传递给提示模板组件。 -
将其他组件连接到流程的其余部分:
- 将网络搜索组件的输出连接到类型转换组件的输入。
- 将类型转换组件的输出连接到提示模��板组件的context输入。
-
在语言模型组件中,添加您的OpenAI API密钥。
如果您想使用不同的提供商或模型,请相应地编辑模型提供商、模型名称和API密钥字段。
-
点击Playground,然后询问与您的搜索查询相关的内容,例如
latest news或what's the latest research on the environment?。结果
LLM使用搜索结果上下文、您的聊天消息及其内置训练数据来回答您的问题。 例如:
_10以下是一些与环境相关的最新新闻文章:_10臭氧污染与全球变暖:最近的一项研究强调,臭氧污染是一个重大的全球环境问题,威胁人类健康和农作物生产,同时加剧全球变暖。阅读更多_10...
类型转换参数
| 名称 | 显示名称 | 信息 |
|---|---|---|
| input_data | 输入数据 | 输入参数。要转换的数据。接受Data、DataFrame或Message输入。 |
| output_type | 输出类型 | 输入参数。所需的输出类型,可以是Data、DataFrame或Message之一。 |
| output | 输出 | 输出参数。以指定格式转换后的数据。输出端口根据所选的Output Type而变化。 |
传统处理组件
以下Processing组件是传统组件。 您仍然可以在工作流中使用它们,但它们已不再受支持,并且可能在未来的版本中被移除。
请尽快用建议的替代组件替换这些组件。
修改元数据
请用Data Operations组件替换此传统组件。
此组件修改输入对象的元数据。它可以添加新元数据、更新现有元数据以及移除指定的元数据字段。该组件同时支持Message和Data对象,还可以根据用户提供的文本创建新的Data对象。
它接受以下参数:
| Name | Display Name | Info |
|---|---|---|
| input_value | 输入 | 输入参数。要添加元数据的对象。 |
| text_in | 用户文本 | 输入参数。文本输入;值包含在Data对象的'text'属性中。空文本条目将被忽略。 |
| metadata | 元数据 | 输入参数。要添加到每个对象的元数据。 |
| remove_fields | 要移除的字段 | 输入参数。要移除的元数据字段。 |
| data | 数据 | 输出参数。输入对象列表,每个对象都添加了元数据。 |
合并数据/数据合并
请用Data Operations组件或Loop组件替换此传统组件。
此组件将多个数据源合并为单个统一的Data对象。
该组件遍历Data对象列表,将它们合并为一个Data对象(merged_data)。
如果输入列表为空,则返回一个空数据对象。
如果只有一个输入数据对象,则返回该对象(保持不变)。
合并过程使用加法运算符来组合数据对象。
合并文本
请用Data Operations组件替换此传统组件。
此组件使用指定的分隔符将两个文本输入连接为单个文本块,并输出包含合并文本的Message对象。
创建数据
请用Data Operations组件替换此传统组件。
此组件动态创建一个具有指定字段数�和文本键的Data对象。
它接受以下参数:
| Name | Display Name | Info |
|---|---|---|
| number_of_fields | 字段数量 | 输入参数。要添加到记录中的字段数量。 |
| text_key | 文本键 | 输入参数。标识要用作文本内容的字段的键。 |
| text_key_validator | 文本键验证器 | 输入参数。如果启用,检查给定的Text Key是否存在于给定的Data中。 |
提取键
请用Data Operations组件替换此传统组件。
此组件从Data对象中提取特定键并返回与该键关联的值。
数据到DataFrame/数据到消息
请用较新的Processing组件替换这些传统组件,例如Data Operations组件和Type Convert组件。
这些组件将一个或多个Data对象转换为DataFrame或Message对象。
对于数据到DataFrame组件,每个Data对象对应结果DataFrame中的一行。
来自.data属性的字段成为列,.text字段(如果存在)被放置在text列中。
筛选数据
请用Data Operations组件替换此传统组件。
此组件基于键列表(filter_criteria)筛选Data对象,返回一个新的Data对象(filtered_data),其中仅包含符合筛选条件的键值对。
筛选值
请用Data Operations组件替换此传统组件。
筛选值组件根据指定的键、筛选值和比较运算符筛选数据项列表。
它接受以下参数:
| Name | Display Name | Info |
|---|---|---|
| input_data | 输入数据 | 输入参数。要筛选的数据项列表。 |
| filter_key | 筛选键 | 输入参数。要筛选的键。 |
| filter_value | 筛选值 | 输入参数。要筛选的值。 |
| operator | 比较运算符 | 输入参数。用于比较值的运算符。 |
| filtered_data | 筛选后的数据 | 输出参数。筛选后的数据项列表。 |
JSON清理器
请用Parser组件替换此传统组件。
JSON 清理器
此组件清理 JSON 字符串以确保它们完全符合 JSON 规范。
它接受以下参数:
| Name | Display Name | Info |
|---|---|---|
| json_str | JSON 字符串 | 输入参数。需要清理的 JSON 字符串。这可能是语言模型或其他来源生成的原始的、可能格式不正确的 JSON 字符串,可能不完全符合 JSON 规范。 |
| remove_control_chars | 移除控制字符 | 输入参数。如果设置为 True,此选项会从 JSON 字符串中移除控制字符(ASCII 字符 0-31 和 127)。这有助于消除可能导致解析问题或使 JSON 无效的不可见字符。 |
| normalize_unicode | 规范化 Unicode | 输入参数。启用时,此选项将 JSON 字符串中的 Unicode 字符规范化为其标准组合形式(NFC)。这确保了 Unicode 字符在不同系统上的一致表示,并防止了字符编码可能带来的潜在问题。 |
| validate_json | 验证 JSON | 输入参数。如果设置为 True,此选项会尝试解析 JSON 字符串以确保其在应用最终修复操作之前是格式良好的。如果 JSON 无效,它会引发 ValueError,从而能够及早检测 JSON 中的主要结构问题。 |
| output | 清理后的 JSON 字符串 | 输出参数。最终清理、修复和验证的 JSON 字符串,完全符合 JSON 规范。 |
消息转数据
将此传统组件替换为 类型转换 组件。
此组件将 Message 对象转换为 Data 对象。
解析 DataFrame
将此传统组件替换为 DataFrame 操作 组件 或 解析器 组件。
此组件使用模板将 DataFrame 对象转换为纯文本。
它接受以下参数:
| Name | Display Name | Info |
|---|---|---|
| df | DataFrame | 输入参数。要转换为文本行的 DataFrame。 |
| template | 模板 | 输入参数。格式化模板(使用 {column_name} 占位符)。 |
| sep | 分隔符 | 输入参数。用于连接输出行中字符串的分隔符。 |
| text | 文本 | 输出参数。所有行合并为单个文本。 |
解析 JSON
将此传统组件替换为 解析器 组件。
此组件使用 JQ 查询在 Message 和 Data 对象中转换和提取 JSON 字段,然后返回 filtered_data,这是一个 Data 对象列表。
Python REPL
将此传统组件替换为 Python 解释器 组件 或其他处理或逻辑组件。
此组件创建用于执行 Python 代码的 Python REPL(读取-评估-打印循环)工具。
它接受以下参数:
| Name | Type | Description |
|---|---|---|
| name | String | 输入参数。工具的名称。默认值:python_repl。 |
| description | String | 输入参数。工具功能的描述。 |
| global_imports | List[String] | 输入参数。要全局导入的模块列表。默认值:math。 |
| tool | Tool | 输出参数。用于在 LangChain 中使用的 Python REPL 工具。 |
Python 代码结构化
将此传统组件替换为 Python 解释器 组件 或其他处理或逻辑组件。
此组件使用数据类从 Python 代码创建结构化工具。
该组件根据提供的 Python 代码动态更新其配置,允许自定义函数参数和描述。
它接受以下参数:
| Name | Type | Description |
|---|---|---|
| tool_code | String | 输入参数。工具数据类的 Python 代码。 |
| tool_name | String | 输入参数。工具的名称。 |
| tool_description | String | 输入参数。工具的描述。 |
| return_direct | Boolean | 输入参数。是否直接返回函数输出。 |
| tool_function | String | 输入参数。为工具选择的函数。 |
| global_variables | Dict | 输入参数。工具的全局变量或数据。 |
| result_tool | Tool | 输出参数。从 Python 代码创建的结构化工具。 |
正则表达式提取器
将此传统组件替换为 解析器 组件。
此组件使用正则表达式提取文本中的模式。可用于查找和提取文本中的特定模式或信息。
选择数据
将此传统组件替换为 数据操作 组件。此组件从列表中选择单个 Data 对象。
它接受以下参数��:
| Name | Display Name | Info |
|---|---|---|
| data_list | Data List | Input parameter. List of data to select from |
| data_index | Data Index | Input parameter. Index of the data to select |
| selected_data | Selected Data | Output parameter. The selected Data object. |
Update Data
将此传统组件替换为 Data Operations 组件。
此组件动态更新或使用指定字段追加数据。
它接受以下参数:
| Name | Display Name | Info |
|---|---|---|
| old_data | Data | Input parameter. The records to update. |
| number_of_fields | Number of Fields | Input parameter. The number of fields to add. The maximum is 15. |
| text_key | Text Key | Input parameter. The key for text content. |
| text_key_validator | Text Key Validator | Input parameter. Validates the text key presence. |
| data | Data | Output parameter. The updated Data objects. |