Vector Stores
Langflow的Vector Store组件用于读写向量数据,包括嵌入存储、向量搜索、图RAG遍历以及特定于提供商的专业搜索,如OpenSearch、Elasticsearch和Vectara。
这些组件对于向量搜索应用至关重要,例如需要从大型数据集中检索相关上下文的检索增强生成(RAG)聊天机器人。
这些组件中的大多数连接到特定的向量数据库提供商,但某些组件支持多个提供商或平台。 例如,Cassandra向量存储组件可以连接到自管理的基于Apache Cassandra的集群,以及作为托管Cassandra DBaaS的Astra DB。
其他类型的存储,如传统结构化数据库和聊天记忆,则通过其他组件处理,例如SQL Database组件或Message History组件。
在流程中使用向量存储组件
有关在�流程中使用向量存储组件的教程,请参阅创建向量RAG聊天机器人。
以下步骤介绍在流程中使用向量存储组件的方法,包括配置详情、组件在运行流程时的运作方式、为什么可能需要在单个流程中使用多个向量存储组件,以及有用的支持组件,如嵌入模型和解析器组件。
-
使用向量存储RAG模板创建流程。
此模板有两个子流程。 加载数据子流程将嵌入和内容加载到向量数据库中,而检索器子流程运行向量搜索以根据用户查询检索相关上下文。
-
为两个Astra DB组件配置数据库连接,或用您选择的其他一对向量存储组件替换它们。 确保组件连接到同一个向量存储,并且检索器子流程中的组件能够运行相似性搜索。
您在每个向量存储组件中设置的参数取决于该组件在流程中的角色。 在此示例中,加载数据子流程向向量存储中写入数据,而检索器子流程从向量存储中读取数据。 因此,搜索相关参数仅与检索器子流程中的向量搜索组件相关。
有关特定配置参数的信息,请参阅本页中您选择的向量存储组件部分和隐藏参数。
-
要配置嵌入模型,请执行以下操作之一:
-
使用OpenAI模型:在两个OpenAI嵌入组件中,输入您的OpenAI API密钥。 您可以使用默认模型或选择其他OpenAI嵌入模型。
-
使用其他提供商:将OpenAI嵌入组件替换��为您选择的另一对嵌入模型组件,然后相应地配置参数和凭据。
-
使用Astra DB向量化:如果您使用的是具有向量化集成的Astra DB向量存储,则可以移除两个OpenAI嵌入组件。 如果这样做,向量化集成将自动从摄取数据(在加载数据子流程中)和搜索查询(在检索器子流程中)生成嵌入。
提示如果您的向量存储已包含嵌入,请确保您的嵌入模型组件使用与之前嵌入相同的模型。 在同一个向量存储中混合使用嵌入模型可能会产生不准确的搜索结果。
-
-
建议:在分割文本组件中,为您的嵌入模型优化分块设置。 例如,如果您的嵌入模型的token限制为512,则块大小参数不得超过该限制。
此外,由于检索器子流程将聊天输入直接传递给向量存储组件进行向量搜索,请确保您的聊天输入字符串不超过嵌入模型的限制。 在此示例中,您可以输入限制范围内的查询;但是,在生产环境中,您可能需要实施额外的检查或预处理步骤以确保合规性。 例如,在运行向量搜索之前使用其他组件准备聊天输入,或在应用程序代码中强制执行聊天输入限制。
-
在语言模型组件中,输入您的OpenAI API密钥,或选择不同的提供商和模型用于流程的聊天部分。
-
运行加载数据子流程以填充您的向量存储。 在文件组件中,选择一个或多个文件,然后点击加载数据子流程中向量存储组件上的 运行组件。
加载数据子流程从您的本地计算机加载文件,对其进行分块,为这些块生成嵌入,然后将这些块及其嵌入存储在向量数据库中。
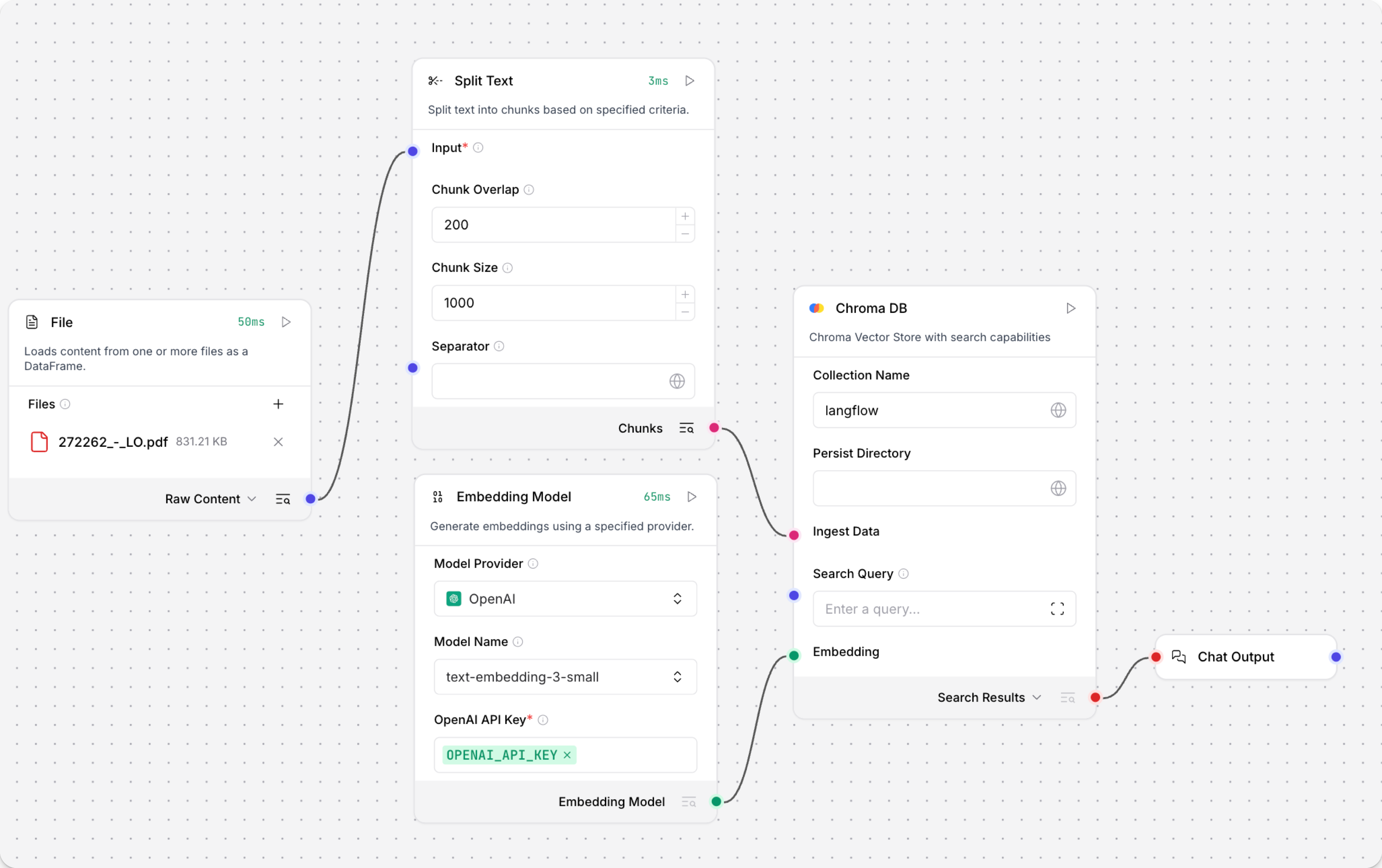
加载数据子流程与检索器子流程是分开的,因为您可能不会每次使用聊天时都运行它。 您可以根据需要运行加载数据子流程,以预加载或更新向量存储中的数据。 然后,您的聊天交互仅使用聊天所需的组件。
如果您的向量存储已包含您想要用于向量搜索的数据,则无需运行加载数据子流程。
-
打开游乐场并开始聊天以运行检索器子flow。Retriever 子流从聊天输入生成嵌入向量,运行向量搜索从向量存储中检索相似内容,将搜索结果解析为 LLM 的补充上下文,然后使用 LLM 生成对您查询的自然语言响应。 LLM 使用向量搜索结果及其内部训练数据和工具(如基础网络搜索和日期时间信息)来生成响应。
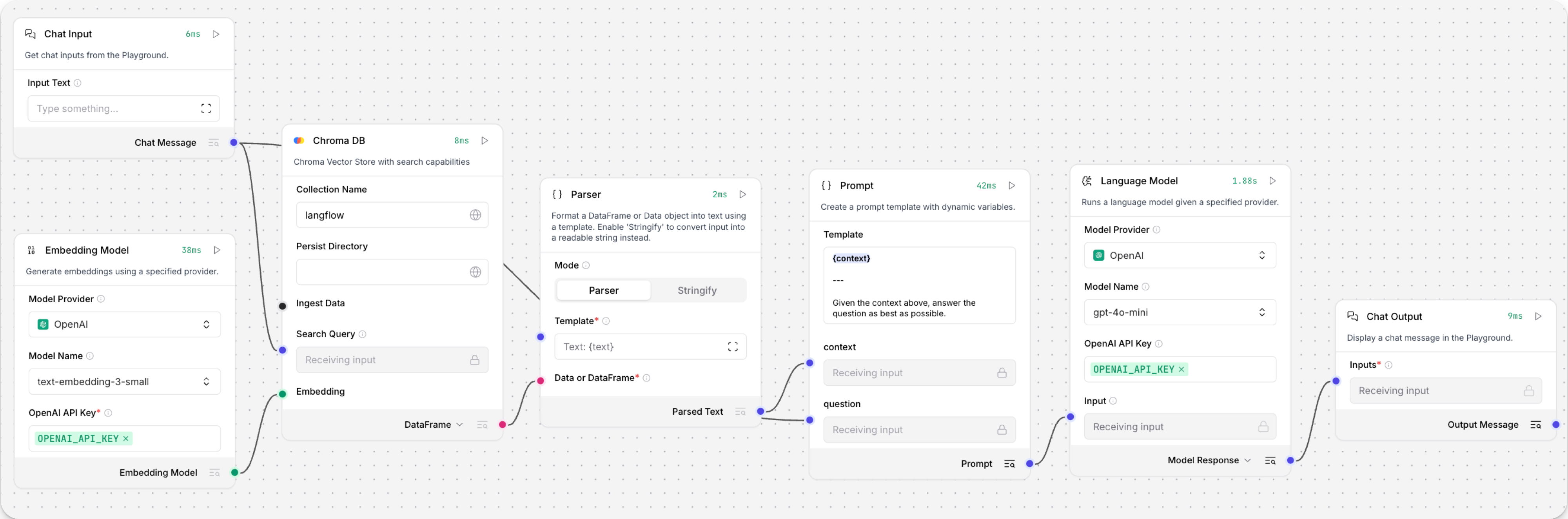
为避免将整个原始搜索结果块传递给 LLM,Parser 组件从搜索结果的
Data对象中提取text字符串,然后以Message格式将它们传递给 Prompt Template 组件。 从那里,字符串和其他模板内容被编译成给 LLM 的自然语言指令。您可以根据如何使用搜索结果,使用其他组件进行此转换,例如 Data Operations 组件。
要查看原始搜索结果,请在运行 Retriever 子流后,点击 Vector Store 组件上的 Inspect output。
隐藏参数
您可以检查 Vector Store 组件的参数,以了解更多它接受的输入、支持的功能以及如何配置它。
在可视化编辑器中,Vector Store 组件的许多输入参数默认是隐藏的。 您可以通过每个组件的标题菜单中的 Controls 来切换参数。
某些参数是条件性的,只有在您设置其他参数或为其他参数选择特定选项后才可用。 在您设置必需的依赖项之前,条件性参数可能不会显示在 Controls 窗格中。 但是,所有参数都会始终列在组件的代码中。
有关特定组件参数的信息,请参阅提供商的文档和组件详情。
搜索结果输出
如果您使用 Vector Store 组件查询您的向量存储,它会生成搜索结果,您可以将这些结果作为 Data 对象列表或表格形式的 DataFrame 传递给流程中的下游组件。
如果支持这两种类型,您可以在可视化编辑器中组件的输出端口附近设置格式。
此模式的例外是 Vectara RAG 组件,它只输出 Message 格式的 answer 字符串。
向量存储实例
由于 Langflow 基于 LangChain,Vector Store 组件使用 LangChain 向量存储 的实例来驱动底层的向量搜索功能。
在组件代码中,这通常被实例化为 vector_store,但某些组件使用不同的名称,例如提供商名称。
对于 Cassandra Graph 和 Astra DB Graph 组件,vector_store 是 LangChain 图向量存储 的实例。
这些实例是特定于提供商的,并根据组件的参数进行配置。
例如,Redis 组件根据组件的参数(如连接字符串、索引名称和架构)创建 RedisVectorStore 的实例。
某些 LangChain 类不会将所有可能的选项作为组件参数公开。 根据提供商的不同,这些选项可能使用默认值,或者如果 Langflow 支持的话,允许通过环境变量进行修改。 有关特定选项的信息,请参阅 LangChain API 参考和提供商文档。
向量存储连接端口
Astra DB 和 OpenSearch 组件有一个额外的 Vector Store Connection 输出。
此输出只能连接到 VectorStore 输入端口,并且旨在�用于专用的 Graph RAG 组件。
支持此输入的唯一非传统组件是 Graph RAG 组件,它旨在作为 Astra DB 组件的 Graph RAG 扩展。 相反,您可以使用包含向量存储连接和 Graph RAG 功能的 Astra DB Graph 组件。 OpenSearch 实例通过内置的 RAG 功能和插件支持图遍历。
Apache Cassandra
Cassandra 和 Cassandra Graph 组件可用于支持向量搜索的 Cassandra 集群,包括 Astra DB。
有关更多信息,请参阅以下内容:
Cassandra
使用 Cassandra 组件通过 CassandraVectorStore 实例来读取或写入 Cassandra 向量存储。
Cassandra 参数
| 名称 | 类型 | 描述 |
|---|---|---|
| database_ref | String | 输入参数。数据库的联系人点或 Astra 数据库 ID。 |
| username | String | 输入参数。数据库的用户名。对于 Astra DB,留空。 |
| token | SecretString | 输入参数。数据库的用户密码或 Astra 应用程序令牌。 |
| keyspace | String | 输入参数。包含在 表名 (table_name) 中指定的向量存储的 keyspace 的名称。 |
| table_name | String | 输入参数。作为向量存储的表或集合的名称。 |
| ttl_seconds | Integer | 输入参数。添加文本的生存时间(如果集群支持)。仅与写入相关。 |
| batch_size | Integer | 输入参数。单个批次中要处理的记录数量。 |
| setup_mode | String | 输入参数。设置 Cassandra 表的配置模式。 |
| cluster_kwargs | Dict | 输入参数。Cassandra 集群的额外关键字参数。 |
| search_query | String | 输入参数。相似性搜索的查询字符串。仅与读取相关。 |
| ingest_data | Data | 输入参数。要作为原始块和嵌入加载到向量存储中的数据。仅与写入相关。 |
| embedding | Embeddings | 输入参数。要使用的嵌入函数。 |
| number_of_results | Integer | 输入参数。搜索中返回的结果数量。仅与读取相关。 |
| search_type | String | 输入参数。要执行的搜索类型。仅与读取相关。 |
| search_score_threshold | Float | 输入参数。搜索结果的最小相似度分数。仅与读取相关。 |
| search_filter | Dict | 输入参数。除了向量搜索外,要应用的元数据搜索过滤器的可选字典。仅与读取相关。 |
| body_search | String | 输入参数。文档文本搜索词。仅与读取相关。 |
| enable_body_search | Boolean | 输入参数。启用文本搜索的标志。仅与读取相关。 |
Cassandra 图
Cassandra 图 组件使用 CassandraGraphVectorStore 实例在兼容的 Cassandra 集群中进行图遍历和基于图的文档检索。
它还支持写入向量存储。
Cassandra 图参数
| 名称 | 显示名称 | 信息 |
|---|---|---|
| database_ref | 联系人点 / Astra 数据库 ID | 输入参数。数据库的联系人点或 Astra 数据库 ID。必需。 |
| username | 用户名 | 输入参数。数据库的用户名。对于 Astra DB,留空。 |
| token | 密码 / Astra DB 令牌 | 输入参数。数据库的用户密码或 Astra 应用程序令牌。必需。 |
| keyspace | Keyspace | 输入参数。包含在 表名 (table_name) 中指定的向量存储的 keyspace 的名称。必需。 |
| table_name | 表名 | 输入参数。作为向量存储的表或集合的名称。必需。 |
| setup_mode | 设置模式 | 输入参数。设置 Cassandra 表的配置模式。选项为 Sync(默认)或 Off。 |
| cluster_kwargs | 集群参数 | 输入参数。Cassandra 集群的额外关键字参数的可选字典。 |
| search_query | 搜索查询 | 输入参数。相似性搜索的查询字符串。仅与读取相关。 |
| ingest_data | 摄入数据 | 输入参数。要作为原始块和嵌入加载到向量存储中的数据。仅与写入相关。 |
| embedding | 嵌入 | 输入参数。要使用的嵌入模型。 |
| number_of_results | 结果数量 | 输入参数。相似性搜索中返回的结果数量。仅与读取相关。默认值:4。 |
| search_type | 搜索类型 | 输入参数。要使用的搜索类型。选项为 Traversal(默认)、MMR Traversal、Similarity、Similarity with score threshold 或 MMR (Max Marginal Relevance)。 |
| depth | 遍历深度 | 输入参数。要遍历的边的最大深度。仅当 搜索类型 (search_type) 为 Traversal 或 MMR Traversal 时相关。默认值:1。 |
| search_score_threshold | 搜索分数阈值 | 输入参数。搜索结果的最小相似度分数阈值。仅在使用 Similarity with score threshold 搜索类型的读取操作中相关。 |
| search_filter | 搜索元数据过滤器 | 输入参数。除了图遍历和相似性搜索外,要应用的元数据搜索过滤器的可选字典。 |
Chroma
Chroma DB 和 Local DB 组件使用 Chroma 向量存储的实例来读写 Chroma 向量存储。
支持远程或内存实例,可选择是否持久化。
有关更多信息,请参阅以下内容:
Chroma DB
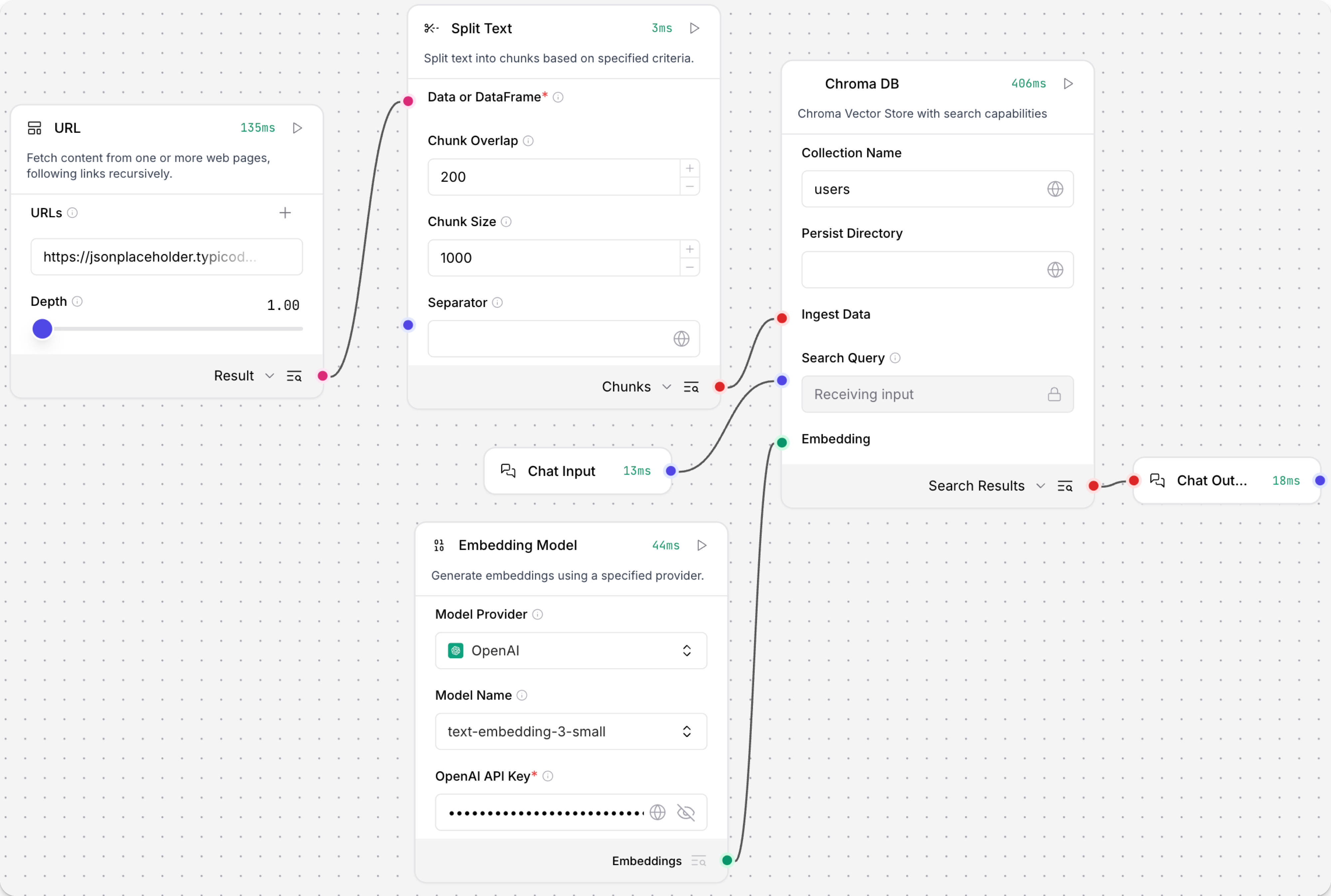
您可以使用 Chroma DB 组件读写本地存储中的 Chroma 数据库或远程 Chroma 服务器,并可选择持久化和缓存选项。 写入时,组件可以在指定位置创建新的数据库或集合。
临时的(非持久化)本地 Chroma 向量存储对于测试向量搜索流程很有用,在这种情况下您不需要保留数据库。
以下示例流程使用一个 Chroma DB 组件同时进行读写操作:
-
写入时,它将来自 URL 组件 的
Data分成块,使用附加的 Embedding Model 组件计算嵌入,然后将块和嵌入加载到 Chroma 向量存储中。 要触发写入,请在 Chroma DB 组件上点击 运行组件。 -
读取时,它使用聊天输入对向量存储执行相似性搜索,然后将搜索结果打印到聊天中。 要触发读取,请打开 Playground 并输入聊天消息。
运行流程一次后,您可以点击每个组件上的 检查输出,以了解数据在组件之间传递时如何转换。
Chroma DB 参数
| 名称 | 类型 | 描述 |
|---|---|---|
集合名称 (collection_name) | 字符串 | 输入参数。您的 Chroma 向量存储集合的名称。默认值:langflow。 |
持久化目录 (persist_directory) | 字符串 | 输入参数。要持久化 Chroma 数据库,请输入用于存储 chroma.sqlite3 文件的相对或绝对路径。留空则创建临时数据库。当读取或写入现有的持久化数据库时,请指定持久化目录的路径。 |
摄取数据 (ingest_data) | 数据或 DataFrame | 输入参数。包含要写入向量存储的记录的 Data 或 DataFrame 输入。仅与写入相关。 |
搜索查询 (search_query) | 字符串 | 输入参数。用于向量搜索的查询。仅与读取相关。 |
缓存向量存储 (cache_vector_store) | 布尔值 | 输入参数。如果为 true,组件会将向量存储缓存在内存中以加快读取速度。默认值:启用 (true)。 |
嵌入 (embedding) | 嵌入 | 输入参数。用于向量存储的嵌入函数。默认情况下,Chroma DB 使用其内置的嵌入模型,或者您可以附加一个 Embedding Model 组件来使用不同的提供商或模型。 |
CORS 允许的源 (chroma_server_cors_allow_origins) | 字符串 | 输入参数。Chroma 服务器的 CORS 允许的源。 |
Chroma 服务器主机 (chroma_server_host) | 字符串 | 输入参数。Chroma 服务器的主机。 |
Chroma 服务器 HTTP 端口 (chroma_server_http_port) | 整数 | 输入参数。Chroma 服务器的 HTTP 端口。 |
Chroma 服务器 gRPC 端口 (chroma_server_grpc_port) | 整数 | 输入参数。Chroma 服务器的 gRPC 端口。 |
Chroma 服务器 SSL 已启用 (chroma_server_ssl_enabled) | 布尔值 | 输入参数。为 Chroma 服务器启用 SSL。 |
允许重复 (allow_duplicates) | 布尔值 | 输入参数。如果为 true(默认值),写入操作不会检查集合中是否已存在重复项,允许您存储同一内容的多个副本。如果为 false,写入操作不会添加与集合中已存在的文档匹配的文档。如果为 false,可以通过搜索整个集合或仅搜索指定数量的记录(在 limit 中指定)来严格强制执行去重。仅与写入相关。 |
搜索�类型 (search_type) | 字符串 | 输入参数。要执行的搜索类型,可以是 Similarity 或 MMR。仅与读取相关。 |
结果数量 (number_of_results) | 整数 | 输入参数。要返回的搜索结果数量。默认值:10。仅与读取相关。 |
限制 (limit) | 整数 | 输入参数。当 允许重复 为 false 时,限制要比较的记录数量。这有助于提高写入大型集合时的性能,但可能导致一些重复记录。仅与写入相关。 |
本地数据库
本地数据库组件用于读写持久化的内存型Chroma DB实例,专为与Langflow一起使用而设计。 它具有独立的读写模式、自动集合管理功能,并默认持久化存储在您的Langflow缓存目录中。
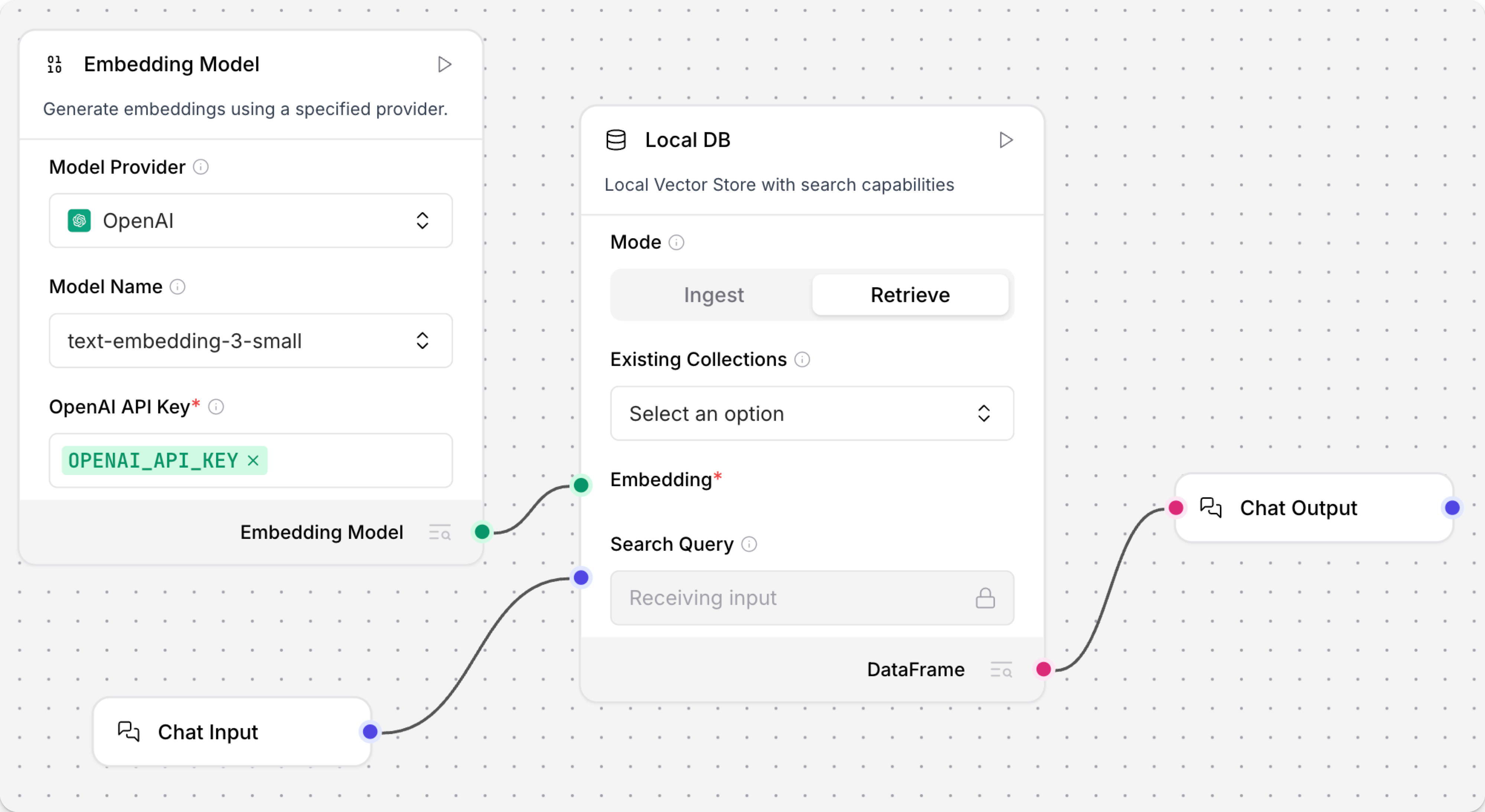
将模式参数设置为反映您希望组件执行的操作,并相应地配置其他参数。 某些参数仅在特定模式下可用。
- Ingest
- Retrieve
要创建或写入本地Chroma向量存储,请使用摄取模式。
摄取模式下提供以下参数:
| Name | Type | Description |
|---|---|---|
Name Your Collection (collection_name) | String | 输入参数。您的Chroma向量存储集合的名称。默认值:langflow。仅在摄取模式下可用。 |
Persist Directory (persist_directory) | String | 输入参数。您想要创建和持久化向量存储的基础目录。如果您在多个流程中使用本地数据库组件或创建多个集合,集合将存储在 $PERSISTENT_DIRECTORY/vector_stores/$COLLECTION_NAME。如果未指定,默认位置是您的Langflow缓存目录(LANGFLOW_CONFIG_DIR)。有关更多信息,请参阅内存管理选项。 |
Embedding (embedding) | Embeddings | 输入参数。用于向量存储的嵌入函数。 |
Allow Duplicates (allow_duplicates) | Boolean | 输入参数。如果为true(默认值),写入操作不会检查集合中是否已存在重复项,允许您存储同一内容的多个副本。如果为false,写入操作不会添加与集合中已存在的文档匹配的文档。如果为false,可以通过搜索整个集合或仅搜索指定在limit中的记录数来严格强制执行去重。仅在摄取模式下可用。 |
Ingest Data (ingest_data) | Data or DataFrame | 输入参数。要写入集合的记录。记录将被嵌入并建立索引以进行语义搜索。仅在摄取模式下可用。 |
Limit (limit) | Integer | 输入参数。当允许重复为false时,限制��要比较的记录数量。这有助于提高写入大型集合时的性能,但可能会导致一些重复记录。仅在摄取模式下可用。 |
要从本地Chroma向量存储中读取数据,请使用检索模式。
检索模式下提供以下参数:
| Name | Type | Description |
|---|---|---|
Persist Directory (persist_directory) | String | 输入参数。您想要创建和持久化向量存储的基础目录。如果您在多个流程中使用本地数据库组件或创建多个集合,集合将存储在 $PERSISTENT_DIRECTORY/vector_stores/$COLLECTION_NAME。如果未指定,默认位置是您的Langflow缓存目录(LANGFLOW_CONFIG_DIR)。有关更多信息,请参阅内存管理选项。 |
Existing Collections (existing_collections) | String | 输入参数。选择先前创建的集合进行搜索。仅在检索模式下可用。 |
Embedding (embedding) | Embeddings | 输入参数。用于向量存储的嵌入函数。 |
Search Type (search_type) | String | 输入参数。要执行的搜索类型,可以是Similarity或MMR。仅在检索模式下可用。 |
Search Query (search_query) | String | 输入参数。输入用于相似性搜索的查询。仅在检索模式下可用。 |
Number of Results (number_of_results) | Integer | 输入参数。要返回的搜索结果数量。默认值:10。仅在检索模式下可用。 |
Clickhouse
Clickhouse 组件使用 Clickhouse 向量存储实例来读写 Clickhouse 向量存储。
有关更多信息,请参阅以下内容:
Clickhouse 参数
| Name | Display Name | Info |
|---|---|---|
| host | hostname | 输入参数。Clickhouse 服务器主机名。必需。默认值:localhost。 |
| port | port | 输入参数。Clickhouse 服务器端口。必需。默认值:8123。 |
| database | database | 输入参数。Clickhouse 数据库名称。必需。 |
| table | Table name | 输入参数。Clickhouse 表名。必需。 |
| username | Username | 输入参数。用于身份验证的 Clickhouse 用户名。必需。 |
| password | Password | 输入参数。用于身份验证的 Clickhouse 密码。必需。 |
| index_type | index_type | 输入参数。索引类型,可以是 annoy(默认)或 vector_similarity。 |
| metric | metric | 输入参数。用于相似性搜索计算距离的度量。选项包括 angular(默认)、euclidean、manhattan、hamming、dot。 |
| secure | Use HTTPS/TLS | 输入参数。如果为 true,则为 Clickhouse 服务器启用 HTTPS/TLS,并覆盖接口或端口参数的推断值。默认值:false。 |
| index_param | Param of the index | 输入参数。索引参数。默认值:100,'L2Distance'。 |
| index_query_params | index query params | 输入参数。额外的索引查询参数。 |
| search_query | Search Query | 输入参数。相似性搜索的查询字符串。仅与读取相关。 |
| ingest_data | Ingest Data | 输入参数。要加载到向量存储中的记录。 |
| cache_vector_store | Cache Vector Store | 输入参数。如果为 true,组件会在内存中缓存向量存储以加快读取速度。默认值:已启用(true)。 |
| embedding | Embedding | 输入参数。要使用的嵌入模型。 |
| number_of_results | Number of Results | 输入参数。要返回的搜索结果数量。默认值:4。仅与读取相关。 |
| score_threshold | Score threshold | 输入参数。相似性分数比较的阈值。默认值:未设置(无阈值)。仅与读取相关。 |
Couchbase
Couchbase 组件使用 CouchbaseSearchVectorStore 实例来读写 Couchbase 向量存储。
有关更多信息,请参阅以下内容:
Couchbase 参数
| Name | Type | Description |
|---|---|---|
| couchbase_connection_string | SecretString | 输入参数。Couchbase 集群连接字符串。必需。 |
| couchbase_username | String | 输入参数。用于身份验证的 Couchbase 用户名。必需。 |
| couchbase_password | SecretString | 输入参数。用于身份验证的 Couchbase 密码。必需。 |
| bucket_name | String | 输入参数。Couchbase bucket 名称。必需。 |
| scope_name | String | 输入参数。Couchbase scope 名称。必需。 |
| collection_name | String | 输入参数。Couchbase collection 名称。必需。 |
| index_name | String | 输入参数。Couchbase 索引名称。必需。 |
| ingest_data | Data | 输入参数。要加载到向量存储中的记录。仅与写入相关。 |
| search_query | String | 输入参数。向量搜索的查询字符串。仅与读取相关。 |
| cache_vector_store | Boolean | 输入参数。如果为 true,组件会在内存中缓存向量存储以加快读取速度。默认值:已启用(true)。 |
| embedding | Embeddings | 输入参数。向量存储要使用的嵌入函数。 |
| number_of_results | Integer | 输入参数。要返回的最大搜索结果数量。默认值:4。仅与读取相关。 |
DataStax
以下组件支持 DataStax 向量存储。
有关更多信息,请参阅以下内容:
Astra DB
Astra DB 组件用于读写 Astra DB Serverless 数据库,使用 AstraDBVectorStore 实例来调用 Data API 和 DevOps API。
建议您在配置 Astra DB 组件之前,先创建所需的数据库、keyspace 和集合。
您可以通过此组件创建新的数据库和集合,但这仅在 Langflow 可视化编辑器中可行,在运行时无法实现,并且在继续配置流程之前,您必须等待数据库或集合初始化完成。 此外,并非所有数据库和集合配置选项都可通过 Astra DB 组件使用,例如混合搜索选项、PCU 组、vectorize 集成管理以及多区域部署。
Astra DB 参数
| Name | Display Name | Info |
|---|---|---|
| token | Astra DB Application Token | 输入参数。一个具有访问向量数据库权限的Astra应用程序令牌。连接验证后,将使用您现有的数据库和集合填充其他字段。如果您要通过此组件创建数据库,应用程序令牌必须具有组织管理员权限。 |
| environment | Environment | 输入参数。Astra DB API端点的环境。始终使用 prod。 |
| database_name | Database | 输入参数。您希望此组件连接到的数据库名称。或者,您可以选择 New Database 创建新数据库,然后等待数据库初始化。 |
| keyspace | Keyspace | 输入参数。数据库中包含collection_name中指定的集合的keyspace。默认值:default_keyspace。 |
| collection_name | Collection | 输入参数。您希望与此流程一起使用的集合名称。或者,选择 New Collection 以使用有限的配置选项创建新集合。为确保您的集合配置了正确的嵌入提供程序和搜索功能,建议在配置此组件之前,在Astra门户或使用数据API创建集合。有关更多信息,请参阅 在Astra DB Serverless中管理集合。 |
| embedding_model | Embedding Model | 输入参数。附加一个Embedding Model组件以生成嵌入。仅在指定的集合没有vectorize集成时可用。如果存在vectorize集成,组件将自动使用集合的集成模型。 |
| ingest_data | Ingest Data | 输入参数。要加载到指定集合中的文档。 |
| search_query | Search Query | 输入参数。向量搜索的查询字符串。 |
| cache_vector_store | Cache Vector Store | 输入参数。是否在Langflow内存中缓存向量存储以实现更快的读取。默认值:已启用(true)。 |
| search_method | Search Method | 输入参数。要使用的搜索方法,可以是Hybrid Search或Vector Search。您的集合必须配置为支持所选选项,默认值取决于您的集合支持的功能。Astra DB Serverless(向量)数据库中的所有集合都支持向量搜索,但混合搜索要求您在创建集合时设置特定的集合设置。这些选项仅在以编程方式创建集合时可用。有关更多信息,请参阅 在Astra DB Serverless中查找数据的方法 和 创建支持混合搜索的集合。 |
| reranker | Reranker | 输入参数。用于混合搜索的重新排序模型,取决于集合配置。即使所选集合不支持混合搜索,此参数也会显示默认的重新排序器。 要验证集合是否支持混合搜索,获取集合元数据,然后检查lexical和rerank是否都具有"enabled": true。 |
| lexical_terms | Lexical Terms | 输入参数。用于混合搜索的关键字空格分隔字符串,如features, data, attributes, characteristics。此参数仅在集合支持混合搜索时可用。有关更多信息,请参阅以下混合搜索示例。 |
| number_of_results | Number of Search Results | 输入参数。要返回的搜索结果数量。默认值:4。 |
| search_type | Search Type | 输入参数。要使用的搜索类型,可以是Similarity(默认)、Similarity with score threshold和MMR (Max Marginal Relevance)。 |
| search_score_threshold | Search Score Threshold | 输入参数。对于使用Similarity with score threshold搜索类型的向量搜索结果的最小相似度分数阈值。默认值:0。 |
| advanced_search_filter | Search Metadata Filter | 输入参数。除了向量或混合搜索外,要应用的可选元数据过滤器字典。 |
| autodetect_collection | Autodetect Collection | 输入参数。在提供应用程序令牌和API端点后,是否自动获取可用集合的列表。 |
| content_field | Content Field | 输入参数。对于写入操作,此参数指定文档中包含您要为其生成嵌入的文本字符串的字段名称。 |
| ignore_invalid_documents | 忽略无效文档 | 输入参数。是否在写入过程中忽略无效文档。如果禁用(false),则对无效文档引发错误。默认值:已启用(true)。 |
| astradb_vectorstore_kwargs | AstraDBVectorStore 参数 | 输入参数。一个可选的字典,用于为 AstraDBVectorStore 实例提供额外参数。有关更多信息,请参阅 Vector store instances。 |
混合搜索示例
Astra DB 组件支持 Data API 的 混合搜索 功能。 混合搜索执行向量相似性搜索和词汇搜索,比较两种搜索的结果,然后返回最相关的整体结果。
要通过 Astra DB 组件使用混合搜索,请执行以下操作:
-
如果您尚未创建集合,请使用 Data API 创建支持混合搜索的集合。
虽然您可以通过 Astra DB 组件创建集合,但使用 Data API 进行此操作时,您对集合设置有更多的控制和洞察。
-
基于 Hybrid Search RAG 模板创建流程,该模板包含一个预配置为混合搜索的 Astra DB 组件。
-
在 Language Model 组件中,添加您的 OpenAI API 密钥。
-
删除连接到 Structured Output 组件的 Input Message 端口的 Language Model 组件,然后将 Chat Input 组件连接到该端口。
-
配置 Astra DB 向量存储组件:
-
输入您的 Astra DB 应用程序令牌。
-
在 Database 字段中,选择您的数据库。
-
在 Collection 字段中,选择启用了混合搜索的集合。
一旦您选择支持混合搜索的集合,其他参数会自动更新以允许混合搜索选项。
-
-
在 组件的头部菜单 中,�点击 Controls,找到 Lexical Terms 字段,启用 Show 切换,然后点击 Close。
-
将第一个 Parser 组件的 Parsed Text 输出连接到 Astra DB 组件的 Lexical Terms 输入。 此输入仅在连接支持混合搜索和重排序的集合后才会出现。
-
点击 Structured Output 组件以显示 组件的头部菜单,点击 Controls,找到 Format Instructions 行,点击 Expand,然后将提示替换为以下文本:
_10You are a database query planner that takes a user's requests, and then converts to a search against the subject matter in question._10You should convert the query into:_101. A list of keywords to use against a Lucene text analyzer index, no more than 4. Strictly unigrams._102. A question to use as the basis for a QA embedding engine._10Avoid common keywords associated with the user's subject matter._10```9. 点击 **Finish Editing**,然后点击 **Close** 以保存您对组件的更改。 -
打开 Playground,然后输入一个关于您的数据库的自然语言问题。
在此示例中,您的输入会同时发送到 Astra DB 和 Structured Output 组件:
-
直接发送到 Astra DB 组件的 Search Query 端口的输入用作相似性搜索的字符串。 使用集合的 Astra DB vectorize 集成从查询字符串生成嵌入向量。
-
发送到 Structured Output 组件的输入由 Structured Output、Language Model 和 Parser 组件处理,以提取用于混合搜索的词汇搜索部分的空格分隔的
keywords。
使用 Data API 的
find_and_rerank命令对您的数据库执行完整的混合搜索查询。 API 的响应输出为DataFrame,然后由另一个 Parser 组件转换为文本字符串Message。 最后,Chat Output 组件将Message响应打印到 Playground。 -
-
可选:退出 Playground,然后点击每个组件上的 Inspect Output,以了解词汇关键词是如何构建的,并查看来自 Data API 的原始响应。 这对于调试某些组件未按预期从另一个组件接收输入的流程很有帮助。
-
Structured Output 组件:输出是通过将输出模式应用于 LLM 对输入消息和格式指令的响应而产生的
Data对象。 以下示例基于上述关键词提取指令:_101. Keywords: features, data, attributes, characteristics_102. Question: What characteristics can be identified in my data? -
Parser 组件:输出是从结构化输出
Data中提取的关键词字符串,然后用作混合搜索的词汇术语。 -
Astra DB 组件:输出是包含 Data API 返回的混合搜索结果的
DataFrame。
-
Astra DB Graph
Astra DB Graph 组件使用一个 AstraDBGraphVectorStore 实例在 Astra DB 集合中进行图遍历和基于图的文档检索。它还支持写入向量存储。
有关更多信息,请参见 使用 LangChain 和 GraphRetriever 构建图 RAG 系统。
Details
Astra DB Graph 参数
| Name | Display Name | Info | |------|--------------|------| | token | Astra DB 应用程序令牌 | 输入参数。具有访问向量数据库权限的 Astra 应用程序令牌。连接验证后,其他字段将填充您现有的数据库和集合。如果要通过此组件创建数据库,应用程序令牌必须具有组织管理员权限。 | | api_endpoint | API 端点 | 输入参数。您的��数据库的 API 端点。 | | keyspace | Keyspace | 输入参数。数据库中包含collection_name 指定集合的 keyspace。默认值:default_keyspace。 |
| collection_name | 集合 | 输入参数。您要与此流程一起使用的集合名称。对于写入操作,如果不存在匹配的集合,则会创建一个新的。 |
| metadata_incoming_links_key | 元数据传入链接键 | 输入参数。向量存储中传入链接的元数据键。 |
| ingest_data | 摄入数据 | 输入参数。要加载到向量存储中的记录。仅与写入操作相关。 |
| search_input | 搜索查询 | 输入参数。用于相似性搜索的查询字符串。仅与读取操作相关。 |
| cache_vector_store | 缓存向量存储 | 输入参数。是否在 Langflow 内存中缓存向量存储以实现更快的读取。默认值:已启用 (true)。 |
| embedding_model | 嵌入模型 | 输入参数。附加一个 嵌入模型 组件 来生成嵌入。如果集合具有 vectorize 集成,请不要附加 嵌入模型 组件。 |
| metric | 度量 | 输入参数。用于相似性搜索计算的度量,可以是 cosine(默认)、dot_product 或 euclidean。这是一个集合设置。 |
| batch_size | 批处理大小 | 输入参数。可选的单个批处理中要处理的记录数。 |
| bulk_insert_batch_concurrency | 批量插入批处理并发性 | 输入参数。批量写入操作的可选并发级别。 |
| bulk_insert_overwrite_concurrency | 批量插入覆盖并发性 | 输入参数。允许更新(覆盖现有记录)的批量写入操作的可选并发级别。 |
| bulk_delete_concurrency | 批量删除并发性 | 输入参数。批量删除操作的可选并发级别。 |
| setup_mode | 设置模式 | 输入参数。设置�向量存储的配置模式,可以是 Sync(默认)或 Off。 |
| pre_delete_collection | 预删除集合 | 输入参数。是否在创建新集合之前删除现有集合。默认值:已禁用 (false)。 |
| metadata_indexing_include | 元数据索引包含 | 输入参数。如果要仅在创建集合时启用选择性索引,则要索引的元数据字段列表。不适用于现有集合。每个集合只能设置一个 *_indexing_* 参数。如果所有 *_indexing_* 参数都未设置,则所有字段都会被索引(默认索引)。 |
| metadata_indexing_exclude | 元数据索引排除 | 输入参数。如果要仅在创建集合时启用选择性索引,则要从索引中排除的元数据字段列表。不适用于现有集合。每个集合只能设置一个 *_indexing_* 参数。如果所有 *_indexing_* 参数都未设置,则所有字段都会被索引(默认索引)。 |
| collection_indexing_policy | 集合索引策略 | 输入参数。如果要仅在创建集合时启用选择性索引,则用于定义索引策略的字典。不适用于现有集合。每个集合只能设置一个 *_indexing_* 参数。如果所有 *_indexing_* 参数都未设置,则所有字段都会被索引(默认索引)。当您需要在子字段上设置索引或使用不兼容列表的复杂索引定义时,使用 collection_indexing_policy 字典。 |
| number_of_results | 结果数量 | 输入参数。要返回的搜索结果数量。默认值:4。仅与读取操作相关。 |
| search_type | 搜索类型 | 输入参数。要使用的搜索类型,可以是 Similarity(相似性)、Similarity with score threshold(带分数阈值的相似性)、MMR (Max Marginal Relevance)(最大边际相关性��)、Graph Traversal(图遍历)或 MMR (Max Marginal Relevance) Graph Traversal(最大边际相关性图遍历)(默认)。仅与读取操作相关。 |
| search_score_threshold | 搜索分数阈值 | 输入参数。如果 search_type 为 Similarity with score threshold,则搜索结果的最小相似性分数阈值。默认值:0。 |
| search_filter | 搜索元数据过滤器 | 输入参数。除了向量搜索外还要应用的可选元数据过滤器字典。 |Graph RAG
Graph RAG 组件使用 GraphRetriever 的实例进行 Graph RAG 遍历,从而在 Astra DB 向量存储中实现基于图的文档检索。
有关更多信息,请参阅 DataStax Graph RAG 文档。
此组件原本是作为 Astra DB 向量存储组件的 Graph RAG 扩展。 但是,Astra DB Graph 组件同时包含向量存储连接和 Graph RAG 功能。
Graph RAG 参数
| 名称 | 显示名称 | 信息 |
|---|---|---|
| embedding_model | 嵌入模型 | 输入参数。指定要使用的嵌入模型。如果连接的向量存储具有 vectorize 集成,则不需要此参数。 |
| vector_store | 向量存储连接 | 输入参数。从 Astra DB 组件的 向量存储连接 输出继承的 vector_store 实例。 |
| edge_definition | 边定义 | 输入参数。图遍历的 边定义。 |
| strategy | 遍历策略 | 输入参数。用于图遍历的策略。策略选项从可用策略中动态加载。 |
| search_query | 搜索查询 | 输入参数。要在向量存储中搜索的查询。 |
| graphrag_strategy_kwargs | 策略参数 | 输入参数。用于 检索策略 的附加参数的可选字典。 |
| search_results | 搜索结果 或 DataFrame | 输出参数。基于图的文档检索结果,作为 Data 对象列表或表格形式的 DataFrame。您可以在组件的输出端口附近设置所需��的输出类型。 |
超融合数据库 (HCD)
超融合数据库 (HCD) 组件使用集群的 Data API 服务器来读取和写入 HCD 向量存储。
由于底层函数调用源自 Astra DB 的 Data API,该组件使用 AstraDBVectorStore 的实例。
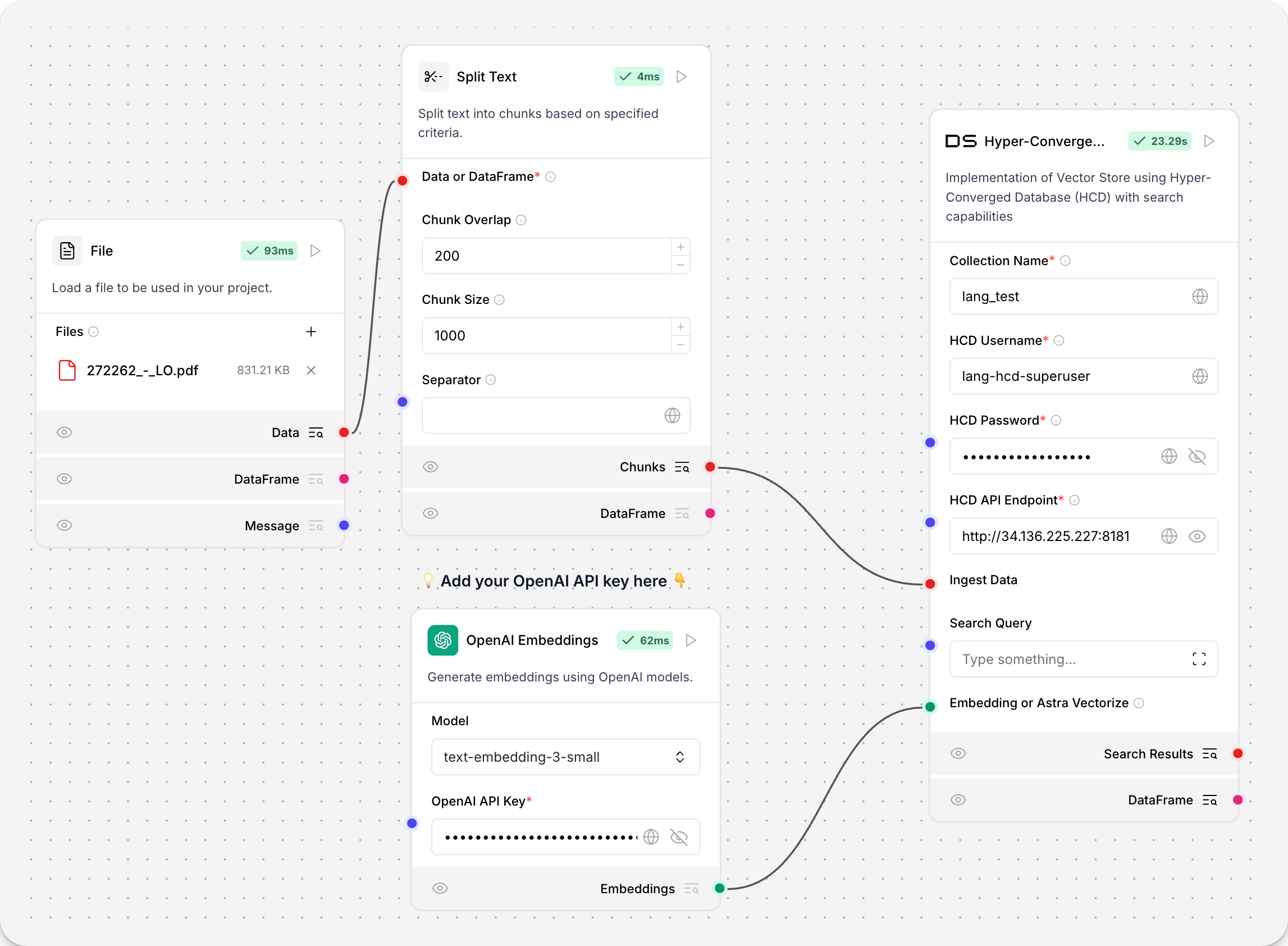
有关将 Data API 与 HCD 部署配合使用的更多信息,请参阅 HCD 1.2 中 Data API 入门。
Details
HCD 参数
| Name | Display Name | Info | |------|--------------|------| | collection_name | 集合名称 | 输入参数。HCD中向量存储集合的名称。对于写入操作,如果集合不存在,则会创建一个新的集合。必需。 | | username | HCD 用户名 | 输入参数。用于验证HCD部署的用户名。默认值:hcd-superuser。必需。 |
| password | HCD 密码 | 输入参数。用于验证HCD部署的密码。必需。 |
| api_endpoint | HCD API 端点 | 输入参数。您的HCD部署的HCD Data API端点,格式为http[s]://**CLUSTER_HOST**:**GATEWAY_PORT**,其中CLUSTER_HOST是集群中任何节点的IP地址,GATEWAY_PORT是API网关服务的端口号。例如,http://192.0.2.250:8181。必��需。 |
| ingest_data | 摄入数据 | 输入参数。要加载到向量存储中的记录。仅与写入操作相关。 |
| search_input | 搜索输入 | 输入参数。用于相似性搜索的查询字符串。仅与读取操作相关。 |
| namespace | 命名空间 | 输入参数。HCD中包含或将要包含collection_name中指定的集合的命名空间。默认值:default_namespace。 |
| ca_certificate | CA 证书 | 输入参数。用于HCD TLS连接的可选CA证书。 |
| metric | 度量 | 输入参数。用于相似性搜索计算的度量,可以是cosine、dot_product或euclidean。这是一个集合设置。如果调用现有集合,请保持未设置以使用集合的度量。如果写入操作创建新集合,请指定所需的相似性度量设置。 |
| batch_size | 批处理大小 | 输入参数。要在单个批处理中处理的可选记录数。 |
| bulk_insert_batch_concurrency | 批量插入批处理并发性 | 输入参数。批量写入操作的可选并发级别。 |
| bulk_insert_overwrite_concurrency | 批量插入覆盖并发性 | 输入参数。允许upsert(覆盖现有记录)的批量写入操作的可选并发级别。 |
| bulk_delete_concurrency | 批量删除并发性 | 输入参数。批量删除操作的可选并发级别。 |
| setup_mode | 设置模式 | 输入参数。设置向量存储的配置模式,可以是Sync(默认)、Async或Off。 |
| pre_delete_collection | 预删除集合 | 输入参数。是否在创建新集合之前删除该集合。 |
| metadata_indexing_include | 元数据索引包含 | 输入参数。要在创建集合时启用选择性索引 仅要索引的元数据字段列表。不适用于现有集合。每个集合只能设置一个*_indexing_*参数。如果所��有*_indexing_*参数都未设置,则所有字段都会被索引(默认索引)。 |
| metadata_indexing_exclude | 元数据索引排除 | 输入参数。要在创建集合时启用选择性索引 仅要从索引中排除的元数据字段列表。不适用于现有集合。每个集合只能设置一个*_indexing_*参数。如果所有*_indexing_*参数都未设置,则所有字段都会被索引(默认索引)。 |
| collection_indexing_policy | 集合索引策略 | 输入参数。要在创建集合时启用选择性索引 仅定义索引策略的字典。不适用于现有集合。每个集合只能设置一个*_indexing_*参数。如果所有*_indexing_*参数都未设置,则所有字段都会被索引(默认索引)。当您需要在子字段上设置索引或与列表不兼容的复杂索引定义时,使用collection_indexing_policy字典。 |
| embedding | 嵌入或Astra Vectorize | 输入参数。通过附加嵌入模型组件使用的嵌入模型。此组件不支持额外的vectorize认证头,因此即使您在现有HCD集合上启用了vectorize集成,也无法使用此组件进行vectorize集成。 |
| number_of_results | 结果数量 | 输入参数。要返回的搜索结果数量。默认值:4。仅与读取操作相关。 |
| search_type | 搜索类型 | 输入参数。要使用的搜索类型,可以是Similarity(默认)、Similarity with score threshold或MMR (Max Marginal Relevance)。仅与读取操作相关。 |
| search_score_threshold | 搜索分数阈值 | 输入参数。如果search_type为Similarity with score threshold,则搜索结果的最小相似性分数阈值。默认值:0。 |
| search_filter | 搜索元数据过滤器 | 输入参数。要应用于向量搜索的可选元数据过滤器字典。 |Elasticsearch
Elasticsearch 组件使用 ElasticsearchStore 读取和写入 Elasticsearch 实例。
有关更多信息,请参阅以下内容:
Elasticsearch 参数
| Name | Type | Description |
|---|---|---|
| es_url | String | 输入参数。Elasticsearch 服务器 URL。 |
| es_user | String | 输入参数。Elasticsearch 认证的用户名。 |
| es_password | SecretString | 输入参数。Elasticsearch 认证的密码。 |
| index_name | String | 输入参数。Elasticsearch 索引的名称。 |
| strategy | String | 输入参数。向量搜索策略,可以是 approximate_k_nearest_neighbors 或 script_scoring。 |
| distance_strategy | String | 输入参数。距离计算策略,可以是 COSINE、EUCLIDEAN_DISTANCE 或 DOT_PRODUCT。 |
| search_query | String | 输入参数。相似性搜索的查询字符串。 |
| ingest_data | Data | 输入参数。要加载到向量存储中的记录。 |
| embedding | Embeddings | 输入参数。要使用的嵌入模型。 |
| number_of_results | Integer | 输入参数。要返回的搜索结果数量。默认值:4。 |
FAISS
FAISS 组件通过 FAISS 向量存储实例提供对 Facebook AI Similarity Search (FAISS) 库的访问。
有关更多信息,请参阅以下内容:
FAISS 参数
| Name | Type | Description |
|---|---|---|
| index_name | String | 输入参数。FAISS 索引的名称。默认值:"langflow_index"。 |
| persist_directory | String | 输入参数。保存 FAISS 索引的路径。该路径相对于 Langflow 运行的位置。 |
| search_query | String | 输入参数。要在向量存储中搜索的查询。 |
| ingest_data | Data | 输入参数。要加载到向量存储中的数据列表。 |
| allow_dangerous_deserialization | Boolean | 输入参数。设置为 True 以允许从不受信任的源加载 pickle 文件。默认值:True。 |
| embedding | Embeddings | 输入参数。向量存储要使用的嵌入函数。 |
| number_of_results | Integer | 输入参数。要从搜索中返回的结果数量。默认值:4。 |
Milvus
Milvus 组件使用 Milvus 向量存储的实例来读取和写入 Milvus 向量存储。
有关更多信息,请参阅以下内容:
Milvus parameters
| Name | Type | Description |
|---|---|---|
| collection_name | String | 输入参数。Milvus 集合的名称。 |
| collection_description | String | 输入参数。Milvus 集合的描述。 |
| uri | String | 输入参数。Milvus 的连接 URI。 |
| password | SecretString | 输入参数。Milvus 的密码。 |
| username | SecretString | 输入参数。Milvus 的用户名。 |
| batch_size | Integer | 输入参数。单个批次中要处理的数据数量。 |
| search_query | String | 输入参数。相似性搜索的查询。 |
| ingest_data | Data | 输入参数。要导入到向量存储的数据。 |
| embedding | Embeddings | 输入参数。要使用的嵌入函数。 |
| number_of_results | Integer | 输入参数。搜索中返回的结果数量。 |
| search_type | String | 输入参数。要执行的搜索类型。 |
| search_score_threshold | Float | 输入参数。搜索结�果的最小相似度分数。 |
| search_filter | Dict | 输入参数。搜索查询的元数据过滤器。 |
| setup_mode | String | 输入参数。设置向量存储的配置模式。 |
| vector_dimensions | Integer | 输入参数。向量的维度数量。 |
| pre_delete_collection | Boolean | 输入参数。是否在创建新集合前删除现有集合。 |
MongoDB Atlas
MongoDB Atlas 组件使用 MongoDBAtlasVectorSearch 实例来读取和写入 MongoDB Atlas 向量存储。
有关更多信息,请参阅以下内容:
MongoDB Atlas parameters
| Name | Type | Description |
|---|---|---|
| mongodb_atlas_cluster_uri | SecretString | 输入参数。MongoDB Atlas 集群的连接 URI。必需。 |
| enable_mtls | Boolean | 输入参数。启用双向 TLS 认证。默认值:false。 |
| mongodb_atlas_client_cert | SecretString | 输入参数。用于 mTLS 认证的客户端证书与私钥的组合。如果启用 mTLS 则为必需。 |
| db_name | String | 输入��参数。要使用的数据库名称。必需。 |
| collection_name | String | 输入参数。要使用的集合名称。必需。 |
| index_name | String | 输入参数。Atlas Search 索引的名称,它应该是向量搜索。必需。 |
| insert_mode | String | 输入参数。如何将新文档插入到集合中。选项为 "append" 或 "overwrite"。默认值:"append"。 |
| embedding | Embeddings | 输入参数。要使用的嵌入模型。 |
| number_of_results | Integer | 输入参数。相似性搜索中返回的结果数量。默认值:4。 |
| index_field | String | 输入参数。要索引的字段。默认值:"embedding"。 |
| filter_field | String | 输入参数。用于过滤索引的字段。 |
| number_dimensions | Integer | 输入参数。嵌入上下文长度。默认值:1536。 |
| similarity | String | 输入参数。用于测量向量之间相似度的方法。选项为 "cosine"、"euclidean" 或 "dotProduct"。默认值:"cosine"。 |
| quantization | String | 输入参数。量化通过将 32 位浮点数转换为更小的数据类型来减少内存成本。选项为 "scalar" 或 "binary"。 |
OpenSearch
OpenSearch 组件使用 OpenSearchVectorSearch 读取和写入 OpenSearch 实例。
有关更多信息,请参阅以下内容:
OpenSearch 参数
| Name | Type | Description |
|---|---|---|
| opensearch_url | String | 输入参数。OpenSearch 集群的 URL,例如 https://192.168.1.1:9200。 |
| index_name | String | 输入参数。向量在 OpenSearch 集群中存储的索引名称。 |
| search_input | String | 输入参数。输入搜索查询。如果使用混合搜索或要检索所有文档,则留空。 |
| ingest_data | Data | 输入参数。要摄取到向量存储的数据。 |
| embedding | Embeddings | 输入参数。要使用的嵌入函数。 |
| search_type | String | 输入参数。选项包括 "similarity"、"similarity_score_threshold"、"mmr"。 |
| number_of_results | Integer | 输入参数。搜索中返回的结果数量。 |
| search_score_threshold | Float | 输入参数。搜索结果的最小相似度分数阈值。 |
| username | String | 输入参数。开源集群的用户名。 |
| password | SecretString | 输入参数。开源集群的密码。 |
| use_ssl | Boolean | 输入参数。使用 SSL。 |
| verify_certs | Boolean | 输入参数。验证证书。 |
| hybrid_search_query | String | 输入参数。以 JSON 格式提供自定义混合搜索查询。这允许您结合向量相似性和关键词匹配。 |
PGVector
PGVector 组件使用 PGVector 实例读取和写入 PostgreSQL 向量存储。
有关更多信息,请参阅以下内容:
PGVector 参数
| Name | Type | Description |
|---|---|---|
| pg_server_url | SecretString | 输入参数。PostgreSQL 服务器连接字符串。 |
| collection_name | String | 输入参数。向量存储的表名。 |
| search_query | String | 输入参数。相似度搜索的查询。 |
| ingest_data | Data | 输入参数。要摄取到向量存储的数据。 |
| embedding | Embeddings | 输入参数。要使用的嵌入函数。 |
| number_of_results | Integer | 输入参数。搜索中返回的结果数量。 |
Pinecone
Pinecone 组件使用 PineconeVectorStore 实例读取和写入 Pinecone 向量存储。
有关更多信息,请参阅以下内容:
Pinecone 参数
| Name | Type | Description |
|---|---|---|
| index_name | String | 输入参数。Pinecone 索引的名称。 |
| namespace | String | 输入参数。索引的命名空间。 |
| distance_strategy | String | 输入参数。计算向量之间距离的策略。 |
| pinecone_api_key | SecretString | 输入参数。Pinecone 的 API 密钥。 |
| text_key | String | 输入参数。记录中用作文本的键。 |
| search_query | String | 输入参数。相似度搜索的查询。 |
| ingest_data | Data | 输入参数。要摄取到向量存储的数据。 |
| embedding | Embeddings | 输入参数。要使用的嵌入函数。 |
| number_of_results | Integer | 输入参数。搜索中返回的结果数量。 |
Qdrant
Qdrant 组件使用 QdrantVectorStore 实例来读写 Qdrant 向量存储。
有关更多信息,请参阅以下内容:
Qdrant 参数
| Name | Type | Description |
|---|---|---|
| collection_name | String | 输入参数。Qdrant 集合的名称。 |
| host | String | 输入参数。Qdrant 服务器主机。 |
| port | Integer | 输入参数。Qdrant 服务器端口。 |
| grpc_port | Integer | 输入参数。Qdrant gRPC 端口。 |
| api_key | SecretString | 输入参数。Qdrant 的 API 密钥。 |
| prefix | String | 输入参数。Qdrant 的前缀。 |
| timeout | Integer | 输入参数。Qdrant 操作的超时时间。 |
| path | String | 输入参数。Qdrant 的路径。 |
| url | String | 输入参数。Qdrant 的 URL。 |
| distance_func | String | 输入参数。向量相似度的距离函数。 |
| content_payload_key | String | 输入参数。内容负载键。 |
| metadata_payload_key | String | 输入参数。元数据负载键。 |
| search_query | String | 输入参数。相似度搜索的查询。 |
| ingest_data | Data | 输入参数。要导入到向量存储的数据。 |
| embedding | Embeddings | 输入参数。要使用的嵌入函数。 |
| number_of_results | Integer | 输入参数。搜索中返回的结果数量。 |
Redis
Redis 组件使用 Redis 向量存储实例来读写 Redis 向量存储。
有关更多信息,请参阅以下内容:
Redis 参数
| Name | Type | Description |
|---|---|---|
| redis_server_url | SecretString | 输入参数。Redis 服务器连接字符串。 |
| redis_index_name | String | 输入参数。Redis 索引的名称。 |
| code | String | 输入参数。Redis 的自定义代码(高级)。 |
| schema | String | 输入参数。Redis 索引的架构。 |
| search_query | String | 输入参数。相似度搜索的查询。 |
| ingest_data | Data | 输入参数。要导入到向量存储的数据。 |
| number_of_results | Integer | 输入参数。搜索中返回的结果数量。 |
| embedding | Embeddings | 输入参数。要使用的嵌入函数。 |
Supabase
Supabase 组件使用 SupabaseVectorStore 实例来读取和写入 Supabase 向量存储。
有关更多信息,请参阅以下内容:
Supabase 参数
| Name | Type | Description |
|---|---|---|
| supabase_url | String | Input parameter. The URL of the Supabase instance. |
| supabase_service_key | SecretString | Input parameter. The service key for Supabase authentication. |
| table_name | String | Input parameter. The name of the table in Supabase. |
| query_name | String | Input parameter. The name of the query to use. |
| search_query | String | Input parameter. The query for similarity search. |
| ingest_data | Data | Input parameter. The data to be ingested into the vector store. |
| embedding | Embeddings | Input parameter. The embedding function to use. |
| number_of_results | Integer | Input parameter. The number of results to return in search. |
Upstash
Upstash 组件使用 UpstashVectorStore 实例来读取和写入 Upstash 向量存储。
有关更多信息,请参阅以下内容:
Upstash 参数
| Name | Type | Description |
|---|---|---|
| index_url | String | Input parameter. The URL of the Upstash index. |
| index_token | SecretString | Input parameter. The token for the Upstash index. |
| text_key | String | Input parameter. The key in the record to use as text. |
| namespace | String | Input parameter. The namespace for the index. |
| search_query | String | Input parameter. The query for similarity search. |
| metadata_filter | String | Input parameter. Filter documents by metadata. |
| ingest_data | Data | Input parameter. The data to be ingested into the vector store. |
| embedding | Embeddings | Input parameter. The embedding function to use. |
| number_of_results | Integer | Input parameter. The number of results to return in search. |
Vectara 平台
Vectara 和 Vectara RAG 组件支持 Vectara 向量存储、搜索和 RAG 功能,使用 Vectara 向量存储实例。
有关更多信息,请参阅以下内容:
Vectara
Vectara 组件读取和写入 Vectara 向量存储,然后生成 搜索结果输出。
Vectara 参数
| Name | Type | Description |
|---|---|---|
| vectara_customer_id | String | Input parameter. The Vectara customer ID. |
| vectara_corpus_id | String | Input parameter. The Vectara corpus ID. |
| vectara_api_key | SecretString | Input parameter. The Vectara API key. |
| embedding | Embeddings | Input parameter. The embedding function to use (optional). |
| ingest_data | List[Document/Data] | Input parameter. The data to be ingested into the vector store. |
| search_query | String | Input parameter. The query for similarity search. |
| number_of_results | Integer | Input parameter. The number of results to return in search. |
Vectara RAG
此组件启用 Vectara 的完整端到端 RAG 功能,并支持重排序选项。
此组件使用 Vectara 向量存储来执行向量搜索和重排序功能,然后以 Message 格式输出一个 Answer 字符串。
Weaviate
Weaviate 组件使用 Weaviate 向量存储的实例来读取和写入 Weaviate 向量存储。
�有关更多信息,请参阅以下内容:
Weaviate 参数
| Name | Type | Description |
|---|---|---|
| weaviate_url | String | 输入参数。默认实例 URL。 |
| search_by_text | Boolean | 输入参数。指示是否按文本搜索。 |
| api_key | SecretString | 输入参数。用于身份验证的可选 API 密钥。 |
| index_name | String | 输入参数。可选的索引名称。 |
| text_key | String | 输入参数。默认文本提取键。 |
| input | Document | 输入参数。文档或记录。 |
| embedding | Embeddings | 输入参数。使用的嵌入模型。 |
| attributes | List[String] | 输入参数。可选的附加属性。 |