数据
您可以使用 Langflow 的 Data 组件从各种来源(如文件、API 端点和 URL)将数据引入到您的流程中。 例如:
-
加载文件:使用 File 组件 和 Directory 组件 从文件或目录导入数据。
-
搜索网络:使用 News Search 组件、RSS Reader 组件、Web Search 组件 和 URL 组件 等组件从网络获取数据。
-
进行 API 调用:使用 API Request 组件 和 Webhook 组件 通过 API 触发流程或执行操作。
-
运行 SQL 查询:使用 SQL Database 组件 查询 SQL 数据库。
每个组件执行不同的命令进行检索、处理和类型检查。 有些组件是对您提供的命令的最小包装,而其他组件则包含内置脚本,可以根据变量输入获取和处理数据。 此外,有些组件返回原始数据,而其他组件在输出之前可以转换、重组或验证数据。 这意味着一些相似的组件可能会产生不同的结果。
Data 组件与 Processing 组件 配合使用效果很好,这些组件可以在检索数据后执行额外的解析、转换和验证。
这可以包括基本操作,例如以特定格式保存文件,或更复杂的任务,例如使用 Text Splitter 组件将大文档分解为较小的块,然后再为向量搜索生成嵌入。
在流程中使用 Data 组件
Data 组件在流程中经常使用,因为它们提供了一种灵活的方式来执行常见的基本功能。
您可以使用这些组件在流程中作为独立步骤执行其基本功能,或者将它们连接到 Agent 组件作为工具。
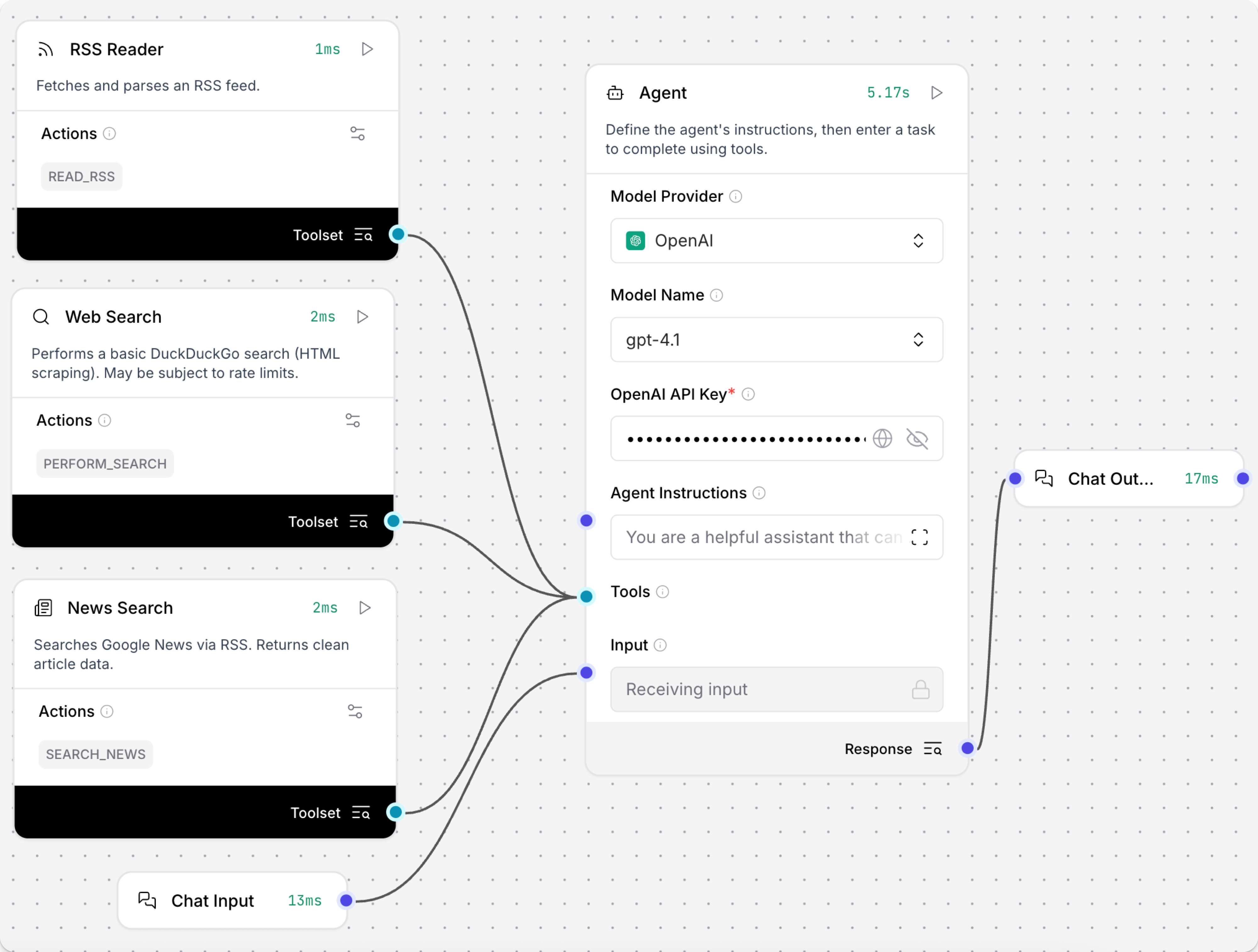
有关示例流程,请参见以下内容:
-
创建可以摄取文件的聊天机器人:了解如何使用 File 组件将文件加载为聊天机器人的上下文。 文件和用户输入都会传递给 LLM,这样您就可以询问有关您上传文件的问题。
-
创建向量 RAG 聊天机器人:了解如何摄取文件用于检索增强生成(RAG),然后设置一个可以使用摄取文件作为上下文的聊天机器人。 本教程中的两个流程为 RAG 准备文件,然后让您的 LLM 在聊天会话期间使用向量搜索检索上下文相关的数据。
-
为代理配置工具:了解如何使用任何组件作为代理的工具。 当用作工具时,代理会根据用户的查询自主决定何时调用组件。
-
使用 Webhook 触发流程:了解如何使用 Webhook 组件响应外部事件来触发流程运行。
API Request
API Request 组件使用 URL 或 curl 命令构建和发送 HTTP 请求:
- URL 模式:输入一个或多个逗号分隔的 URL,然后选择对每个 URL 的请求方法。
- curl 模式:输入要执行的 curl 命令。
您可以在组件的参数中启用额外的请求选项和字段。
返回一个包含响应的 Data 对象。
有关特定于提供程序的 API 组件,请参见 Bundles。
API 请求参数
在可视化编辑器中,部分参数默认情况下是隐藏的。 您可以通过组件的头部菜单中的 控件 来修改所有参数。
| Name | Display Name | Info |
|---|---|---|
| mode | 模式 | 输入参数。将模式设置为 URL 或 curl。 |
| urls | URL | 输入参数。输入一个或多个逗号分隔的URL用于请求。 |
| curl | curl | 输入参数。仅限 curl 模式。输入完整的curl命令。其他组件参数从命令参数中填充。 |
| method | 方法 | 输入参数。要使用的HTTP方法。 |
| query_params | 查询参数 | 输入参数。要附加到URL的查询参数。 |
| body | 请求体 | 输入参数。作为字典发送的POST、PATCH和PUT请求的请求体。 |
| headers | 请求头 | 输入参数。作为字典发送的请求头。 |
| timeout | 超时 | 输入参数。请求使用的超时时间。 |
| follow_redirects | 跟随重定向 | 输入参数。是否跟随HTTP重定向。默认为启用(true)。如果禁用(false),则不跟随HTTP重定向。 |
| save_to_file | 保存到文件 | 输入参数。是否将API响应保存到临时文件。默认:禁用/false |
| include_httpx_metadata | 包含HTTPx元数据 | 输入参数。是否在输出中包含诸如 headers、status_code、response_headers 和 redirection_history 等属性。默认:禁用/false |
�目录
Directory 组件递归地从目录加载文件,提供文件类型、深度和并发性的选项。
文件必须是支持的类型和大小才能被加载。
根据目录内容,输出一个 Data 或 DataFrame 对象。
Directory 参数
在可视化编辑器中,部分参数默认情况下是隐藏的。 您可以通过组件的头部菜单中的 控件 来修改所有参数。
| Name | Type | Description |
|---|---|---|
| path | MessageTextInput | 输入参数。要加载文件的目录路径。默认:当前目录 (.) |
| types | MessageTextInput | 输入参数。要加载的文件类型。选择一个或多个,或留空以尝试加载所有文件。 |
| depth | IntInput | 输入参数。搜索文件的深度。 |
| max_concurrency | IntInput | 输入参数。加载多个文件的最大并发数。 |
| load_hidden | BoolInput | 输入参数。如果为true,则加载隐藏文件。 |
| recursive | BoolInput | 输入参数。如果为true,则搜索是递归的。 |
| silent_errors | BoolInput | 输入参数。如果为true,错误不会引发异常。 |
| use_multithreading | BoolInput | 输入参数。如果为true,则使用多线程。 |
文件
File 组件加载和解析文件,将内容转换为 Data、DataFrame 或 Message 对象。
它支持多种文件类型,并提供并行处理和错误处理的参数。
您可以在可视化编辑器或运行时向 File 组件添加文件,并且可以一次上传多个文件。 有关上传文件以及在流程中使用文件的更多信息,请参阅 文件管理 和 创建可摄取文件的聊天机器人。
文件类型和大小限制
默认情况下,最大文件大小为 100 MB。
要修改此值,请更改 --max-file-size-upload 环境变量。
支持的文件类型
File 组件支持以下文件类型。 使用归档和压缩格式��将多个文件捆绑在一起,或使用 Directory 组件 加载目录中的所有文件。
.bz2.csv.docx.gz.htm.html.json.js.md.mdx.pdf.py.sh.sql.tar.tgz.ts.tsx.txt.xml.yaml.yml.zip
如果您需要加载不支持的文件类型,您必须使用支持该文件类型的其他组件,并且可能在 Langflow 外部解析它,或者在上传之前将其转换为支持的类型。
对于图像,请参阅 上传图像。
对于视频,请在 Langflow 组件 菜单中查看 Twelve Labs 和 YouTube 捆绑包。
文件参数
在可视化编辑器中,部分参数默认情况下是隐藏的。 您可以通过组件的头部菜单中的 控件 来修改所有参数。
| Name | Display Name | Info |
|---|---|---|
| path | Files | 输入参数。要加载的文件的路径。可以是本地路径或在 Langflow 文件管理 中。支持单个文件和捆绑的存档。 |
| file_path | Server File Path | 输入参数。一个具有指向 Langflow 文件管理 中文件的 file_path 属性的 Data 对象,或一个包含文件路径的 Message 对象。替代 Files (path) 但支持相同的文件类型。 |
| separator | Separator | 输入参数。在 Message 格式的多个输出之间使用的分隔符。 |
| silent_errors | Silent Errors | 输入参数。如果为 true,组件中的错误不会引发异常。默认为 false/禁用。 |
| delete_server_file_after_processing | Delete Server File After Processing | 输入参数。如果为 true(默认),处理完成后将删除 Server File Path (file_path)。 |
| ignore_unsupported_extensions | Ignore Unsupported Extensions | 输入参数。如果启用(true),接受但不处理具有不支持扩展名的文件。如果禁用(false),File 组件在提供不支持的文件类型时可能会引发错误。默认为 true。 |
| ignore_unspecified_files | Ignore Unspecified Files | 输入参数。如果为 true,忽略没有 file_path 属性的 Data。如果为 false(默认),当未指定文件时组件会出错�。 |
| concurrency_multithreading | Processing Concurrency | 输入参数。如果上传了多个文件,要同时处理的文件数量。默认为 1。大于 1 的值将为 2 个或更多文件启用并行处理。 |
文件输出
File 组件的输出取决于加载的文件数量和类型:
-
无文件:引发错误,或者如果启用了 Silent Errors,则不产生任何输出。
-
单个文件:根据文件类型产生以下输出之一。如果有多种类型可用,您可以通过单击输出字段(靠近组件的输出端口)来选择输出类型。
- 结构化内容:适用于某些表格和结构化数据。
对于
.csv文件,产生一个表示表格数据的DataFrame。 对于.json文件,产生一个包含已解析 JSON 数据的Data对象。 - 原始内容:一个包含文件原始文本内容的
Message。 - 文件路径:一个包含 Langflow 文件管理 中文件路径的
Message。
- 结构化内容:适用于某些表格和结构化数据。
对于
-
多个文件:产生一个包含所有选定文件内容和元数据的 Files
DataFrame。
新闻搜索
News Search 组件通过 RSS 搜索 Google 新闻,然后返回包含文章标题、链接、发布日期和摘要的干净文章数据作为 DataFrame。
该组件的 clean_html 方法使用 BeautifulSoup 库解析 HTML 内容,移除 HTML 标记,并去除空白字符以输出干净的数据。
对于其他 RSS 源,请使用 RSS Reader 组件,对于其他搜索,请使用 Web Search 组件 或特定于提供商的 bundle。
当在流程中用作标准组件时,News Search 组件必须连接到接受 DataFrame 输入的组件。
您可以将 News Search 组件直接连接到兼容的组件,或者使用 Processing 组件 在组件之间转换或提取不同类型的数据。
当与 Agent 组件一起在 Tool Mode 中使用时,News Search 组件可以直接连接到 Agent 组件的 Tools 端口,而无需转换数据。
代理根据用户的查询决定是否使用 News Search 组件,并且可以直接处理 DataFrame 输出。
新闻搜索参数
在可视化编辑器中,部分参数默认情况下是隐藏的。 您可以通过组件的头部菜单中的 控件 来修改所有参数。
| Name | Display Name | Info |
|---|---|---|
| query | Search Query | Input parameter. Search keywords for news articles. |
| hl | Language (hl) | Input parameter. Language code, such as en-US, fr, de. Default: en-US. |
| gl | Country (gl) | Input parameter. Country code, such as US, FR, DE. Default: US. |
| ceid | Country:Language (ceid) | Input parameter. Language, such as US:en, FR:fr. Default: US:en. |
| topic | Topic | Input parameter. One of: WORLD, NATION, BUSINESS, TECHNOLOGY, ENTERTAINMENT, SCIENCE, SPORTS, HEALTH. |
| location | Location (Geo) | Input parameter. City, state, or country for location-based news. Leave blank for keyword search. |
| timeout | Timeout | Input parameter. Timeout for the request in seconds. |
| articles | News Articles | Output parameter. A DataFrame with the key columns title, link, published and summary. |
RSS阅读器
RSS阅读器组件从任�何有效的RSS源URL获取并解析RSS源,然后将源内容作为包含文章标题、链接、发布日期和摘要的DataFrame返回。
当在流程中用作标准组件时,RSS阅读器组件必须连接到接受DataFrame输入的组件。
您可以将RSS阅读器组件直接连接到兼容的组件,或者使用处理组件在组件之间转换或提取不同类型的数据。
当与代理组件一起在工具模式下使用时,RSS阅读器组件可以直接连接到代理组件的工具端口,而无需转换数据。
代理根据用户的查询决定是否使用RSS阅读器组件,并且可以直接处理DataFrame输出。
RSS阅读器参数
| Name | Display Name | Info |
|---|---|---|
| rss_url | RSS Feed URL | Input parameter. URL of the RSS feed to parse, such as https://rss.nytimes.com/services/xml/rss/nyt/HomePage.xml. |
| timeout | Timeout | Input parameter. Timeout for the RSS feed request in seconds. Default: 5. |
| articles | Articles | Output parameter. A DataFrame containing the key columns title, link, published and summary. |
SQL数据库
SQL数据库组件在SQLAlchemy兼容的数据库上执行SQL查询。 它支持任何SQLAlchemy兼容的数据库,如PostgreSQL、MySQL和SQLite。
有关CQL查询,请参见DataStax捆绑包。
使用自然语言提示查询SQL数据库
以下示例演示了如何在流程中使用SQL Database组件,然后修改该组件以通过Agent组件支持自然语言查询。
这使得您可以对任何查询使用相同的SQL Database组件,而不是将其限制为单个手动输入的查询,或者要求用户、应用程序或其他组件提供有效的SQL语法作为输入。 用户无需掌握SQL语法,因为Agent组件会将用户的自然语言提示转换为SQL查询,将查询传递给SQL Database组件,然后将结果返回给用户。
此外,来自应用程序和其他组件的输入无需提取和转换为精确的SQL查询。 相反,您只需要提供足够的上下文,以便代理理解它应该根据传入的数据创建和运行SQL查询。
-
使用您自己的示例数据库或创建一个测试数据库。
创建测试SQL数据库
-
创建一个名为
test.db的数据库:_10sqlite3 test.db -
向数据库添加一些值:
_13sqlite3 test.db "_13CREATE TABLE users (_13id INTEGER PRIMARY KEY,_13name TEXT,_13email TEXT,_13age INTEGER_13);_13_13INSERT INTO users (name, email, age) VALUES_13('John Doe', '[email protected]', 30),_13('Jane Smith', '[email protected]', 25),_13('Bob Johnson', '[email protected]', 35);_13" -
验证数据库已创建并包含您的数据:
_10sqlite3 test.db "SELECT * FROM users;"结果应列出您在上一步中输入的文本数据:
_101|John Doe|[email protected]_102|Jane Smith|[email protected]_103|John Doe|[email protected]_104|Jane Smith|[email protected]```
-
-
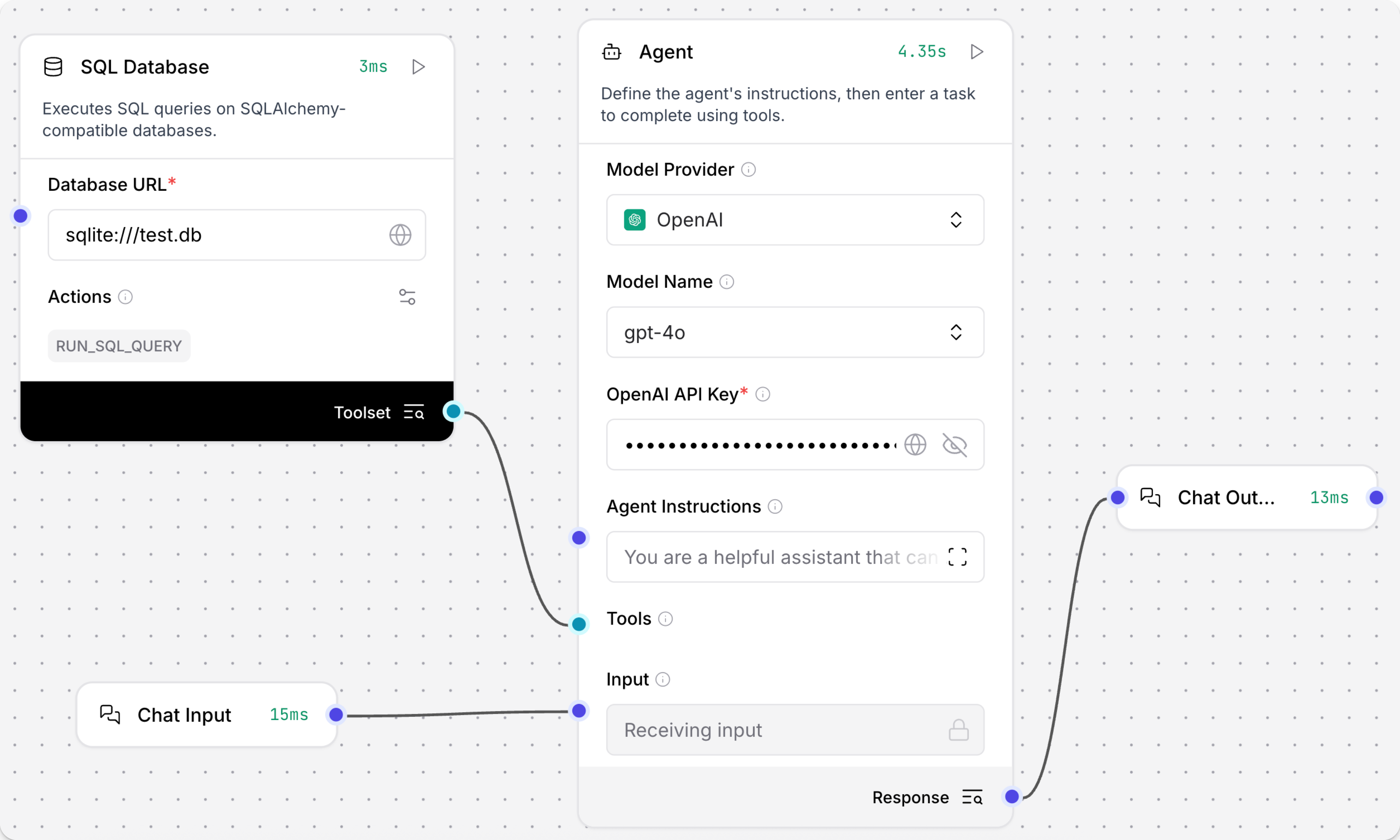
向您的流程中添加一个 SQL Database 组件。
-
在 Database URL 字段中,添加您数据库的连接字符串,例如
sqlite:///test.db�。此时,您可以在 SQL Query 字段中输入 SQL 查询,或者使用 port 从其他组件(如 Chat Input 组件)传递查询。 如果需要更多空间,点击 Expand 以打开全屏文本字段。
但是,为了使此组件在智能体上下文中更加动态,请使用 Agent 组件将自然语言输入转换为 SQL 查询,如下面的步骤所述。
-
点击 SQL Database 组件以显示 组件的头部菜单,然后启用 Tool Mode。
您现在可以将此组件用作智能体的工具。 在 Tool Mode 下,SQL Database 组件中不会设置任何查询,因为智能体会在确定需要该工具来完成用户请求时生成并发送一个查询。 有关更多信息,请参阅 为智能体配置工具。
-
向您的流程中添加一个 Agent 组件,然后输入您的 OpenAI API 密钥。
默认模型是 OpenAI 模型。 如果您想使用不同的模型,请相应地编辑 Model Provider、Model Name 和 API Key 字段。
如果需要执行高度专业的查询,请考虑选择经过高级 SQL 查询等任务训练的模型。 如果您首选的模型不在 Agent 组件的内置模型列表中,请选择 Custom 模型提供商,然后使用 Language Model 组件 来附加特定模型。
-
将 SQL Database 组件的 Toolset 输出连接到 Agent 组件的 Tools 输入。
-
点击 Playground,然后向智能体询问有关您数据库数据的问题,例如
Which users are in my database?智能体确定需要查询数据库来回答问题,使用 LLM 生成 SQL 查询,然后使用 SQL Database 组件的
RUN_SQL_QUERY操作在您的数据库上运行查询。 最后,它会以对话格式返回结果,除非您提供返回原始结果或其他格式的说明。以下示例查询了一个包含少量数据的测试数据库,但使用更强大的数据集,您可以询问更详细或复杂的问题。
_10Here are the users in your database:_10_101. **John Doe** - Email: [email protected]_102. **Jane Smith** - Email: [email protected]_103. **John Doe** - Email: [email protected]_104. **Jane Smith** - Email: [email protected]_10_10It seems there are duplicate entries for the users.
SQL 数据库参数
在可视化编辑器中,部分参数默认情况下是隐藏的。 您可以通过组件的头部菜单中的 控件 来修改所有参数。
| Name | Display Name | Info |
|---|---|---|
| database_url | Database URL | 输入参数。兼容 SQLAlchemy 的数据库连接 URL。 |
| query | SQL Query | 输入参数。要执行的 SQL 查询,可以直接输入、从其他组件传入,或在 Tool Mode 下由 Agent 组件自动提供。 |
| include_columns | Include Columns | 输入参数。是否在结果中包含列名。默认为启用(true)。 |
| add_error | Add Error | 输入参数。如果启用,会将任何错误消息添加到结果中(如果有返回)。默认为禁用(false)。 |
| run_sql_query | Result Table | 输出参数。查询结果,以 DataFrame 形式返回。 |
URL
URL 组件从一个或多个 URL 获取内容,处理内容并以各种格式返回。 它会递归跟随链接到指定深度,并支持以纯文本或原始 HTML 格式输出。
URL 参数
在可视化编辑器中,部分参数默认情况下是隐藏的。 您可以通过组件的头部菜单中的 控件 来修改所有参数。
以下是一些可用的参数:
| Name | Display Name | Info |
|---|---|---|
| urls | URLs | 输入参数。要递归抓取的一个或多个 URL。在可视化编辑器中,点击 Add URL 来添加多个 URL。 |
| max_depth | Depth | 输入参数。控制链接遍历:爬虫将从初始页面向外"点击"多少层。深度为 1 仅限制在给定 URL 的第一页抓取。深度为 2 意味着爬虫抓取第一页以及从第一页直接链接到的所有页面,然后停止。此设置专门控制链接遍历;它不限制 URL 路径段的数量或域名。 |
| prevent_outside | Prevent Outside | 输入参数。如果启用,仅抓取与根 URL 相同域名内的 URL。这可以防止爬虫访问给定 URL 域名之外的站点,即使它们是从抓取页面之一链接的。 |
| use_async | Use Async | 输入参数。如果启用,使用异步加载,这可能会显著更快但可能使用更多系统资源。 |
| format | Output Format | 输入参数。将所需的输出格式设置为 Text 或 HTML。默认为 Text。有关更多信息,请参见 URL 输出。 |
| timeout | Timeout | 输入参数。请求的超时时间(秒)。 |
| headers | Headers | 输入参数。如果需要身份验证或其他用途,随请求一起发送的标头。 |
还有其他可用于错误处理和编码的输入参数。
URL 输出
有两个设置在不同阶段控制 URL 组件的输出:
-
Output Format:此可选参数控制从抓取页面中提取的内容:
- Text (default):组件仅从抓取页面的 HTML 中提取文本。
- HTML:组件提取抓取页面的整个原始 HTML 内容。
-
Output data type:在组件的输出字段(靠近输出端口)中,您可以选择传递给其他组件时传出数据的结构:
当在流程中用作标准组件时,URL 组件必须连接到接受所选输出数据类型(DataFrame 或 Message)的组件。
您可以直接将 URL 组件连接到兼容的组件,或者如果数据类型不直接兼容,可以使用 Type Convert 组件 在将数据传递给其他组件之前将输出转换为另一种类型。
像 Type Convert 这样的 Processing 组件与 URL 组件一起使用很有用,因为它可以从抓取页面中提取大量数据。 例如,如果您只想将特定字段传递给其他组件,可以在将数据传递给其他组件之前,使用 Parser 组件 从抓取页面中仅提取该数据。
当与 Agent 组件一起在 Tool Mode 中使用时,URL 组件可以直接连接到 Agent 组件的 Tools 端口,而无需转换数据。
代理根据用户的查询决定是否使用 URL 组件,并且可以直接处理 DataFrame 或 Message 输出。
Web Search
Web Search 组件使用 DuckDuckGo 的 HTML 爬取接口执行基本的网络搜索。 有关其他搜索 API,请参阅 Bundles。
Web Search 组件使用网络爬取,可能会受到速率限制。
对于生产环境使用,建议使用具有更强大 API 支持的其他搜索组件,例如特定提供商的捆绑包。
在流程中使用 Web Search 组件
以下步骤演示了如何在流程中使用 Web Search 组件的一种方法:
-
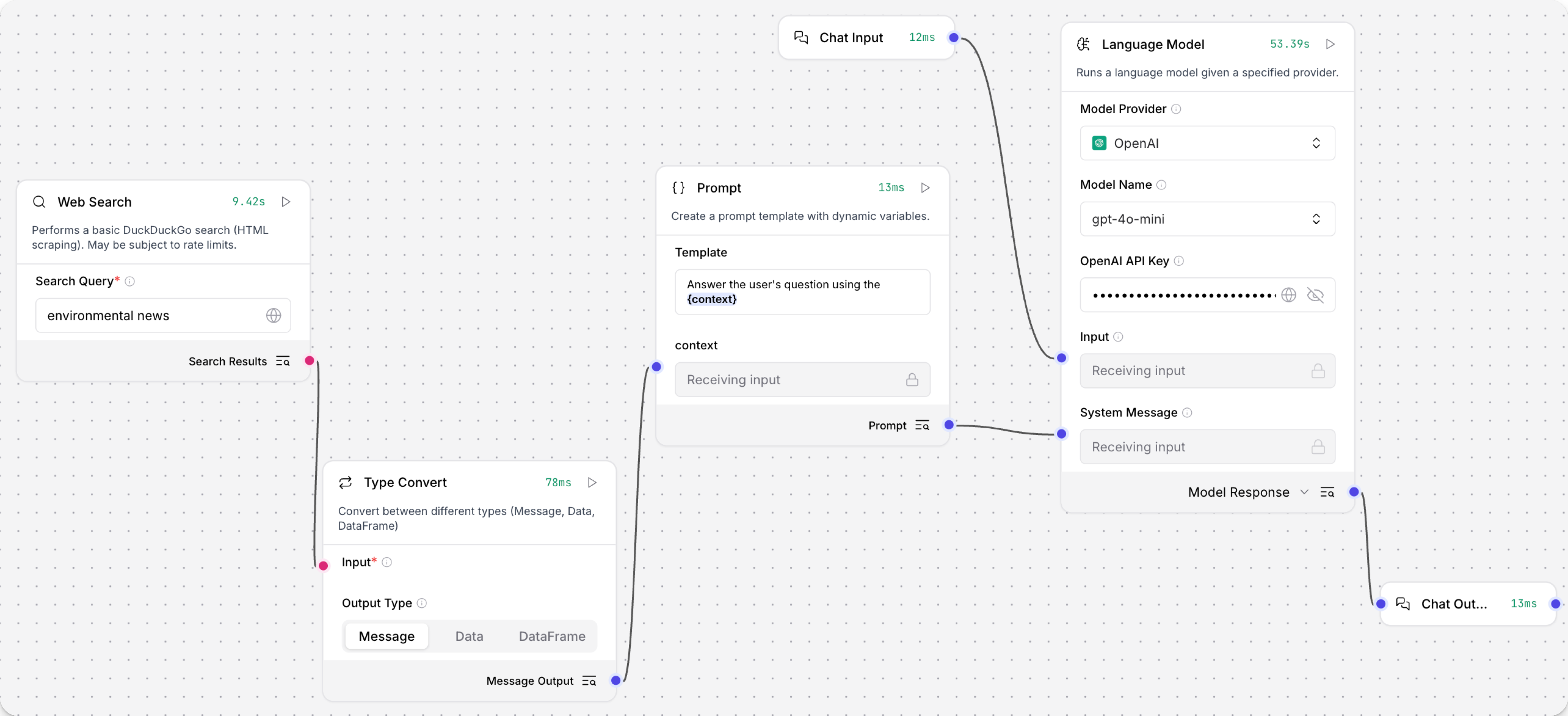
基于 Basic Prompting 模板创建一个流程。
-
添加一个 Web Search 组件,然后输入搜索查��询,例如
environmental news。 -
添加一个 Type Convert 组件,将 Output Type 设置为 Message,然后将 Web Search 组件的输出连接到 Type Convert 组件的输入。
默认情况下,Web Search 组件输出一个
DataFrame。 由于 Prompt Template 组件只接受Message数据,因此需要进行此转换,以便流程可以将搜索结果传递给 Prompt Template 组件。 有关更多信息,请参阅 Web Search output。 -
在 Prompt Template 组件的 Template 字段中,添加一个变量,如
{searchresults}或{context}。这会在 Prompt Template 组件中添加一个字段,您可以使用该字段将转换后的搜索结果传递给提示。
-
将 Type Convert 组件的输出连接到 Prompt Template 组件上的新变量字段。
-
在 Language Model 组件中,添加您的 OpenAI API 密钥,或选择不同的提供商和模型。
-
点击 Playground,然后输入
latest news。LLM 处理请求,包括通过 Prompt Template 组件传递的上下文,然后在 Playground 聊天界面中打印响应。
结果
以下是一个可能的响应示例。 根�据当前网络状态、您的特定查询、模型和其他因素,您的响应可能会有所不同。
_10以下是一些与环境相关的最新新闻文章:_10臭氧污染与全球变暖:最近的一项研究强调,臭氧污染是一个重大的全球环境问题,威胁人类健康和农作物生产,同时加剧全球变暖。阅读更多_10...
Web Search 参数
| Name | Display Name | Info |
|---|---|---|
| query | Search Query | 输入参数。要搜索的关键词。 |
| timeout | Timeout | 输入参数。网络搜索请求的超时时间(秒)。默认值:5。 |
| results | Search Results | 输出参数。返回一个包含 title、links 和 snippets 的 DataFrame。有关更多信息,请参阅 Web Search output。 |
Web Search 输出
Web Search 组件输出一个包含关键列 title、links 和 snippets 的 DataFrame。
在流程中用作标准组件时,Web Search 组件必须连接到接受 DataFrame 输入的组件,或者您必须使用 Type Convert 组件 将输出转换为 Data 或 Message 类型,然后再将数据传递给其他组件。
与 Agent 组件一起在 Tool Mode 中使用时,Web Search 组件可以直接连接到 Agent 组件的 Tools 端口,而无需转换数据。
代理根据用户的查询决定是否使用 Web Search 组件,并且可以直接处理 DataFrame 输出。
Webhook
Webhook 组件定义了一个 webhook 触发器,当收到 HTTP POST 请求时运行流程。
触发 webhook
当您向流程添加 Webhook 组件时,会在流程的 API Access 窗格 中添加一个 Webhook curl 选项卡。 此选项卡会自动生成一个 HTTP POST 请求代码片段,您可以使用它通过 Webhook 组件触发您的流程。 例如:
_10curl -X POST \_10 "http://$LANGFLOW_SERVER_ADDRESS/api/v1/webhook/$FLOW_ID" \_10 -H 'Content-Type: application/json' \_10 -H 'x-api-key: $LANGFLOW_API_KEY' \_10 -d '{"any": "data"}'
有关更多信息,请参阅 使用 webhook 触发流程。
Webhook 参数
| Name | Display Name | Description |
|---|---|---|
| data | Payload | 输入参数。通过 HTTP POST 请求从外部系统接收负载。 |
| curl | curl | 输入参数。用于向此 webhook 发送请求的 curl 命令模板。 |
| endpoint | Endpoint | 输入参数。此 webhook 接收请求的端点 URL。 |
| output_data | Data | 输出参数。来自 webhook 输入的已处理数据。如果没有提供输入,则返回一个空的 Data 对象。如果输入不是有效的 JSON,Webhook 组件会将其包装在 payload 对象中,以便可以作为输入来触发流程。 |
其他数据组件
Langflow 的核心组件旨在具有通用性,支持多种用例。 核心组件通常不限于单个提供商。
如果核心 Data 组件不能满足您的需求,您可以在 Components 菜单的 Bundles 部分找到特定于提供商的组件。
例如,DataStax bundle 包含用于 CQL 查询的组件,而 Google bundle 包含用于 Google Search APIs 的组件。
遗留数据组件
Load CSV 和 Load JSON 组件是遗留组件。 您仍然可以在流程中使用它们,但它们不再被维护,可能会在未来版本中被移除。
使用 File 组件替换这些组件,它支持加载 CSV 和 JSON 文件,以及许多其他文件类型。