DataStax
Bundles 包含支持 Langflow 与特定第三方集成的自定义组件。
本页面描述了 DataStax 包中可用的组件。
Astra DB 聊天记忆
Astra DB 聊天记忆 组件使用 Astra DB 数据库检索和存储聊天消息。
聊天记忆在记忆存储组件之间作为 Memory 数据类型传递。
具体来说,该组件会创建一个 AstraDBChatMessageHistory 实例,这是一个�使用 Astra DB 进行存储的 LangChain 聊天消息历史类。
Astra DB 聊天记忆 组件不推荐用于大多数记忆存储,因为记忆往往是长的 JSON 对象或字符串,经常超过 Astra DB 支持的文档或对象的最大尺寸。
但是,Langflow 的 Agent 组件包含默认启用的内置聊天记忆。 您的智能代理流程不需要外部数据库来存储聊天记忆。 有关更多信息,请参阅 记忆管理选项。
有关在流程中使用外部聊天记忆的更多信息,请参阅 消息历史 组件。
Astra DB 聊天记忆参数
某些组件输入参数在可视化编辑器中默认隐藏。 您可以通过 组件的头部菜单 中的 Controls 来切换参数。
| 名称 | 类型 | 描述 |
|---|---|---|
| collection_name | String | 输入参数。用于存储消息的 Astra DB 集合名称。必需。 |
| token | SecretString | 输入参数。用于 Astra DB 访问的身份验证令牌。必需。 |
| api_endpoint | SecretString | 输入参数。Astra DB 服务的 API 端点 URL。必需。 |
| namespace | String | 输入参数。Astra DB 中集合的可选命名空间。 |
| session_id | MessageText | 输入参数。聊天会话的唯一标识符。如果未提供,则使用当前会话 ID。 |
Astra DB CQL
Astra DB CQL 组件允许代理从 Astra DB 中的 CQL 表查询数据。
输出是一个包含来自 Astra DB CQL 表查询结果的 Data 对象列表。每个 Data 对象包含由投影字段指定的文档字段。受 number_of_results 参数限制。
Astra DB CQL 参数
某些组件输入参数在可视化编辑器中默认隐藏。 您可以通过 组件的头部菜单 中的 Controls 来切换参数。
| 名称 | 类型 | 描述 |
|---|---|---|
| Tool Name | String | 输入参数。在代理提示中引用工具时使用的名称。 |
| Tool Description | String | 输入参数。工具的简要描述,用于指导模型使用它。 |
| Keyspace | String | 输入参数。密钥空间的名称。 |
| Table Name | String | 输入参数。要查询的 Astra DB CQL 表的名称。 |
| Token | SecretString | 输入参数。Astra DB 的身份验证令牌。 |
| API Endpoint | String | 输入参数。Astra DB API 端点。 |
| Projection Fields | String | 输入参数。要返回的属性,用逗号分隔。默认值:"*"。 |
| Partition Keys | Dict | 输入参数。模型必须填写以查询工具的必需参数。 |
| Clustering Keys | Dict | 输入参数。模型可以填写以优化查询的可选参数。必需参数应用感叹号标记,例如 !customer_id。 |
| Static Filters | Dict | 输入参数。用于过滤查询结果的属性值对。 |
| Limit | String | 输入参数。要返回的记录数。 |
Astra DB 工具
Astra DB 工具组件支持在 Astra DB 集合中搜索数据,包括混合搜索、向量搜索和基于常规过滤器的搜索。 专业搜索需要预先配置集合所需的参数。
输出包含来自 Astra DB 查询结果的 Data 对象列表。每个 Data 对象包含由投影属性指定的文档字段。受 number_of_results 参数和 Astra DB 数据 API 上限的限制,具体取决于搜索类型。
您可以使用该组件在流程中直接执行查询作为独立步骤,或者将其作为代理工具连接,以便代理根据需要从 Astra DB 集合中查询数据以响应用户查询。 有关更多信息,请参阅使用 Langflow 代理。
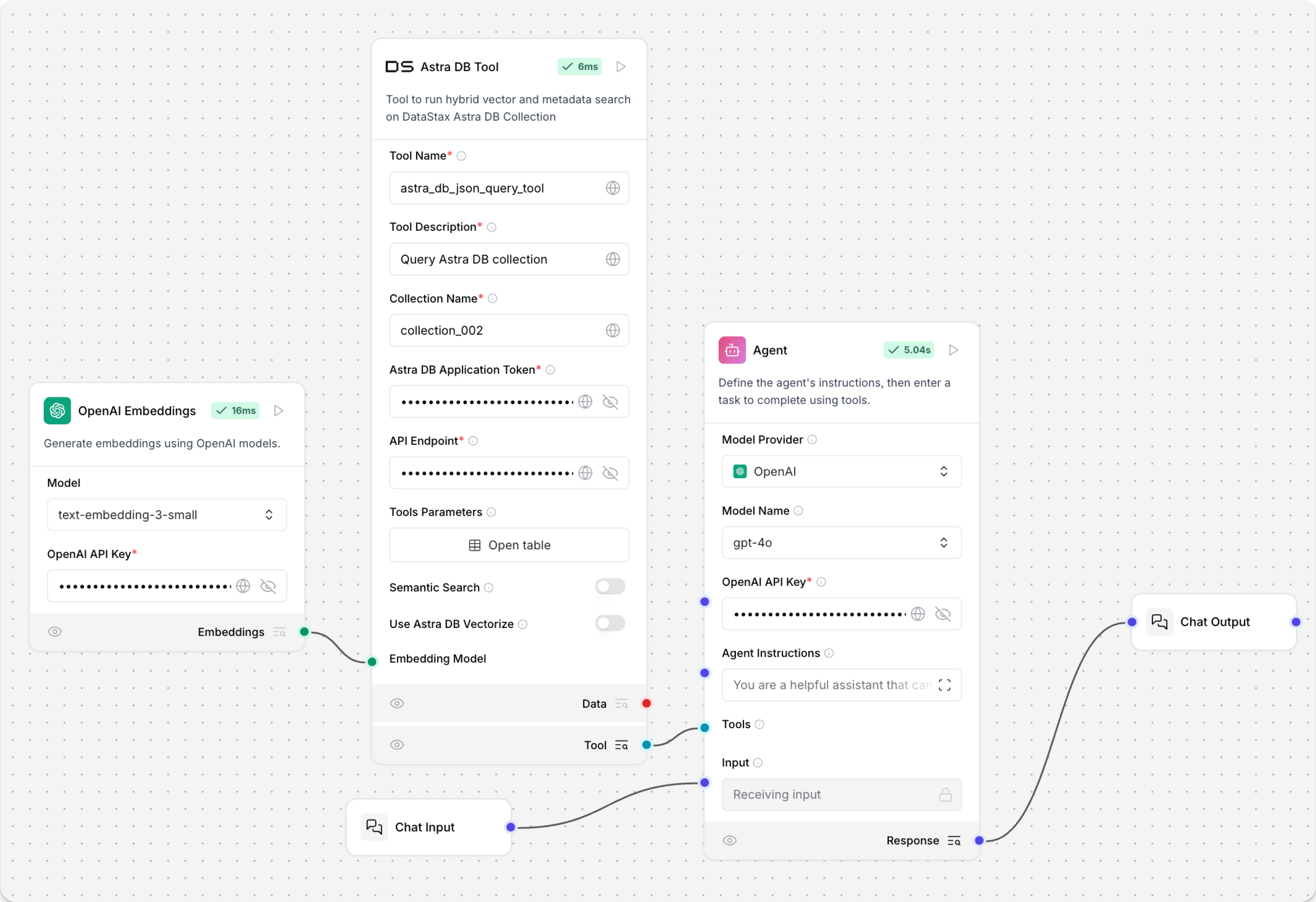
Astra DB 工具参数
以下参数适用于 Astra DB 工具组件整体。
集合名称、Astra DB 应用程序令牌和Astra DB API 端点的值可在您的 Astra DB 部署中找到。有关更多信息,请参阅 Astra DB Serverless 文档。
| 名称 | 类型 | 描述 |
|---|---|---|
| 工具名称 | String | 输入参数。在代理提示中引用工具时使用的名称。 |
| 工具描述 | String | 输入参数。工具的简要描述。这有助于模型决定何时使用它。 |
| Keyspace 名称 | String | 输入参数。Astra DB 中的 keyspace 名称。默认值:default_keyspace |
| 集合名称 | String | 输入参数。要查询的 Astra DB 集合的名称。 |
| 令牌 | SecretString | 输入参数。用于访问 Astra DB 的身份验证令牌。 |
| API 端点 | String | 输入参数。Astra DB API 端点。 |
| 投影字段 | String | 输入参数。从匹配文档返回的属性逗号分隔列表。默认为默认投影 *,它返回除 $vector 等保留字段之外的所有属性。 |
| 工具参数 | Dict | 输入参数。成为代理工具的 Astra DB 数据 API find 过滤器。如果代理选择这些过滤器,则 可能 在搜索中使用它们。请参阅定义工具特定参数。 |
| 静态过滤器 | Dict | 输入参数。用于过滤查询结果的属性-值对。相当于 Astra DB 数据 API find 过滤器。静态过滤器包含在_每次_查询中。使用静态过滤器而不进行语义搜索以执行常规过滤器搜索。 |
| 结果数量 | Int | 输入参数。要返回的最大文档数。 |
| 语义搜索 | Boolean | 输入参数。是否通过从��聊天输入生成向量嵌入并遵循语义搜索指令来运行相似性搜索。默认值:false。如果为 true,则必须附加嵌入模型组件或在集合上预先启用向量化功能。 |
| 使用 Astra DB 向量化 | Boolean | 输入参数。在运行语义搜索时是否使用 Astra DB 向量化功能进行嵌入生成。默认值:false。如果为 true,则必须在集合上预先启用向量化功能。 |
| 嵌入模型 | Embedding | 输入参数。用于连接嵌入模型组件的端口,以便为语义搜索从输入文本生成向量。当语义搜索为 true 时,可以使用或不使用向量化功能。请确保使用与集合中现有嵌入维度一致的模型。 |
| 语义搜索指令 | String | 输入参数。用于相似性搜索的查询。默认值:"查找与查询相似的文档。"。此指令用于指导模型执行语义搜索。 |
定义工具特定参数
工具参数是您在Astra DB 工具组件中创建的小型函数。 它们为 LLM 提供了预定义的方式来与您集合中的数据进行交互。
如果没有这些过滤器,LLM 将无法理解您集合中的数据,也不知道哪些属性是重要的。
在运行时,LLM 可以决定哪些过滤器与当前查询相关。
工具参数中的过滤器并不总是会被应用。 如果您希望对_每个_查询强制应用过滤器,请使用静态过滤器参数。 您可以同时使用工具参数和静态过滤器来设置一些必需的过滤器和一些可选的过滤器。
在Astra DB 工具组件的工具参数字段中,您可以创建过滤器来查询集合中的文档。
当与代理一起在工具模式下使用时,这些过滤器会告诉代理哪些文档属性最重要,哪些属性在搜索中是必需的,以及哪些属性应使用哪些操作符。 这些过滤器会作为参数提供给 LLM 在调用工具时使用,每个参数的用途由描述字段提供更好的理解。
在工具参数窗格中,点击 添加新行,然后编辑该行中的每个单元格。
例如,以下过滤器允许 LLM 根据唯一的 customer_id 值进行过滤:
- 名称:
customer_id - 属性名称: 如果属性与数据库中的字段名称匹配,则留空。
- 描述:
"要过滤的客户唯一标识符"��。 - 是否为元数据: 除非值存储在元数据字段中,否则选择False。
- 是否为必需项: 设置为True以使过滤器成为必需的。
- 是否为时间戳: 对于此示例,选择False,因为该值是 ID 而非时间戳。
- 操作符:
$eq用于查找精确匹配。
工具参数窗格中的每一行都有以下可用字段:
| 参数 | 描述 |
|---|---|
| 名称 | 暴露给 LLM 的参数名称。它可以与底层字段名称相同,也可以使用更具描述性的标签。LLM 使用此名称以及描述来推断在执行时应提供什么值。 |
| 属性名称 | 当显示给 LLM 的参数名称与数据库中的实际字段或属性不同时,使用此设置将面向用户的名称映射到正确的属性。例如,要对时间戳字段应用范围过滤器,请定义两个单独的参数,如 start_date 和 end_date,它们都引用同一个时间戳属性。 |
| 描述 | 向 LLM 提供关于如何使用该参数的说明。清晰具体的指导有助于 LLM 提供有效的输入。例如,如果像 specialty 这样的字段以小写形式存储,则描述应指示输入必须为小写。 |
| 是否为元数据 | 当使用 LangChain 或 Langflow 加载数据时,其他属性可能存储在元数据对象下。如果目标属性以这种方式存储,请启用此选项。它会通过生成格式为 {"metadata.<attribute_name>": "<value>"} 的过滤器来调整查询。 |
| 是否为时间戳 | 对于基于日期或时间的过滤器,启用此选项可自动将值转换为 Astrapy 客户端期望的时间戳格式。这确保了与底层 API 的兼容性,而无需手动格式化。 |
| 操作符 | 定义应用于属性的过滤逻辑。您可以使用任何有效的数据 API 过滤器操作符。例如,要在时间戳属性上过滤时间范围,请使用两个参数:一个使用 $gt 操作符表示"大于",另一个使用 $lt 操作符表示"小于"。 |
Cassandra 聊天记忆
Cassandra 聊天记忆组件使用基于 Apache Cassandra 的数据库(包括 Astra DB 和超融合数据库 (HCD))来检索和存储聊天消息。
聊天记忆作为 Memory 数据类型在内存存储组件之间传递。
具体来说,该组件会创建一个 CassandraChatMessageHistory 实例,这是一个使用 Cassandra 数据库进行存储的 LangChain 聊天消息历史类。
有关在流程中使用外部聊天记忆的更多信息,请参阅消息历史组件。
Cassandra 聊天内存参数
在可视化编辑器中,某些组件输入参数默认是隐藏的。 您可以通过组件标题菜单中的 Controls 来切换参数显示。
| Name | Type | Description |
|---|---|---|
| database_ref | MessageText | 输入参数。Cassandra 数据库的联系人点或 Astra DB 数据库 ID。必需。 |
| username | MessageText | 输入参数。Cassandra 的用户名。Astra DB 留空。 |
| token | SecretString | 输入参数。Cassandra 的密码或 Astra DB 的令牌。必需。 |
| keyspace | MessageText | 输入参数。Cassandra 中的 keyspace 或 Astra DB 中的命名空间。必需。 |
| table_name | MessageText | 输入参数。用于存储消息的表或集合的名称。必需。 |
| session_id | MessageText | 输入参数。聊天会话的唯一标识符。可选。 |
| cluster_kwargs | Dictionary | 输入参数。Cassandra 集群配置的其他关键字参数。可选。 |
DataStax 助手组件
以下 DataStax 组件用于在流程中创建和管理 Assistants API 函数:
- Astra Assistant Agent
- Create Assistant
- Create Assistant Thread
- Get Assistant Name
- List Assistants
- Run Assistant
DataStax 环境变量组件
以下 DataStax 组件用于在流程中加载和检索环境变量:
- Dotenv
- Get Environment Variable
旧版 DataStax 组件
以下组件被视为旧版或已弃用。 这些组件已停止开发,可能会在未来的版本中移除。
请尽快用建议的替代方案替换它们。
Astra DB Vectorize
此组件在 Langflow 版本 1.1.2 中已弃用。 请尽快替换为 Astra DB 向量存储组件。
Astra DB Vectorize 组件曾用于结合 Astra DB 向量存储组件,使用 Astra DB 的 vectorize 功能生成嵌入向量。
现在 vectorize 功能已内置到 Astra DB 向量存储组件中。 您不再需要单独的组件来生成向量嵌入。