将 NVIDIA Retriever Extraction 与 Langflow 集成
NVIDIA Retriever Extraction 组件与 NVIDIA nv-ingest 微服务集成,用于文本文件的数据摄取、处理和提取。
nv-ingest 服务支持 PDF、DOCX 和 PPTX 文件类型的多种提取方法,并包括分割、分块和嵌入生成等预处理和后处理服务。提取器服务的高分辨率模式使用 nemoretriever-parse 提取方法,以从扫描的 PDF 文档中实现更高质量的提取。此功能仅适用于 PDF 文件。
NVIDIA Retriever Extraction 组件导入 NVIDIA Ingestor 客户端,通过向 NVIDIA 摄取端点发送请求来摄取文件,并将处理后的内容作为 Data 对象列表输出。Ingestor 接受其他文本格式的数据提取的额外配置选项。要配置这些选项,请参阅 组件参数。
NVIDIA Retriever Extraction 也称为 NV-Ingest 和 NeMo Retriever Extraction。
先决条件
-
NVIDIA Ingest 端点。有关设置 NVIDIA Ingest 端点的更多信息,请参阅 NVIDIA Ingest 快速入门。
-
NVIDIA Retriever Extraction 组件需要在您的 Langflow 环境中安装额外的依赖项。要在虚拟环境中安装依赖项,请运行以下命令。
- 如果您已克隆并从源代码安装了 Langflow 仓库:
_10source **YOUR_LANGFLOW_VENV**/bin/activate_10uv sync --extra nv-ingest_10uv run langflow run- 如果您从 Python 包索引安装 Langflow:
_10source **YOUR_LANGFLOW_VENV**/bin/activate_10uv pip install --prerelease=allow 'langflow[nv-ingest]'_10uv run langflow run
在工作流中使用 NVIDIA Retriever Extraction 组件
NVIDIA Retriever Extraction 组件接受 Message 输入,然后输出 Data。该组件调用 NVIDIA Ingest 微服务的端点来摄取本地文件并提取文本。
要在您的工作流中使用 NVIDIA Retriever Extraction 组件,请按照以下步骤操作:
-
将 NVIDIA Retriever Extraction 组件添加到您的工作流中。
-
在 Base URL 字段中,输入 NVIDIA Ingest 端点的 URL。 您还可以将 URL 存储为 全局变量,以便在多个组件和工作流中重复使用。
-
点击 Select Files 选择要摄取的文件。
-
选择要从文件中提取的文本类型:文本、图表、表格、图像或信息图。
-
可选:对于 PDF 文件,启用 High Resolution Mode 以从扫描的文档中实现更高质量的提取。
-
选择是否将文本分割为块。
在可视化编辑器中,部分参数默认情况下是隐藏的。 您可以通过组件的头部菜单中的 控件 来修改所有参数。
-
点击 Run component 摄取文件,然后点击 Logs 或 Inspect output 确认组件已摄取文件。
-
要将处理后的数据存储在向量数据库中,请向您的工作流添加一个 Vector Store 组件,然后将 NVIDIA Retriever Extraction 组件的
Data输出连接到 Vector Store 组件的输入。当您使用 Vector Store 组件运行工作流时,处理后的数据将存储在向量数据库中。 您可以查询您的数据库以检索上传的数据。
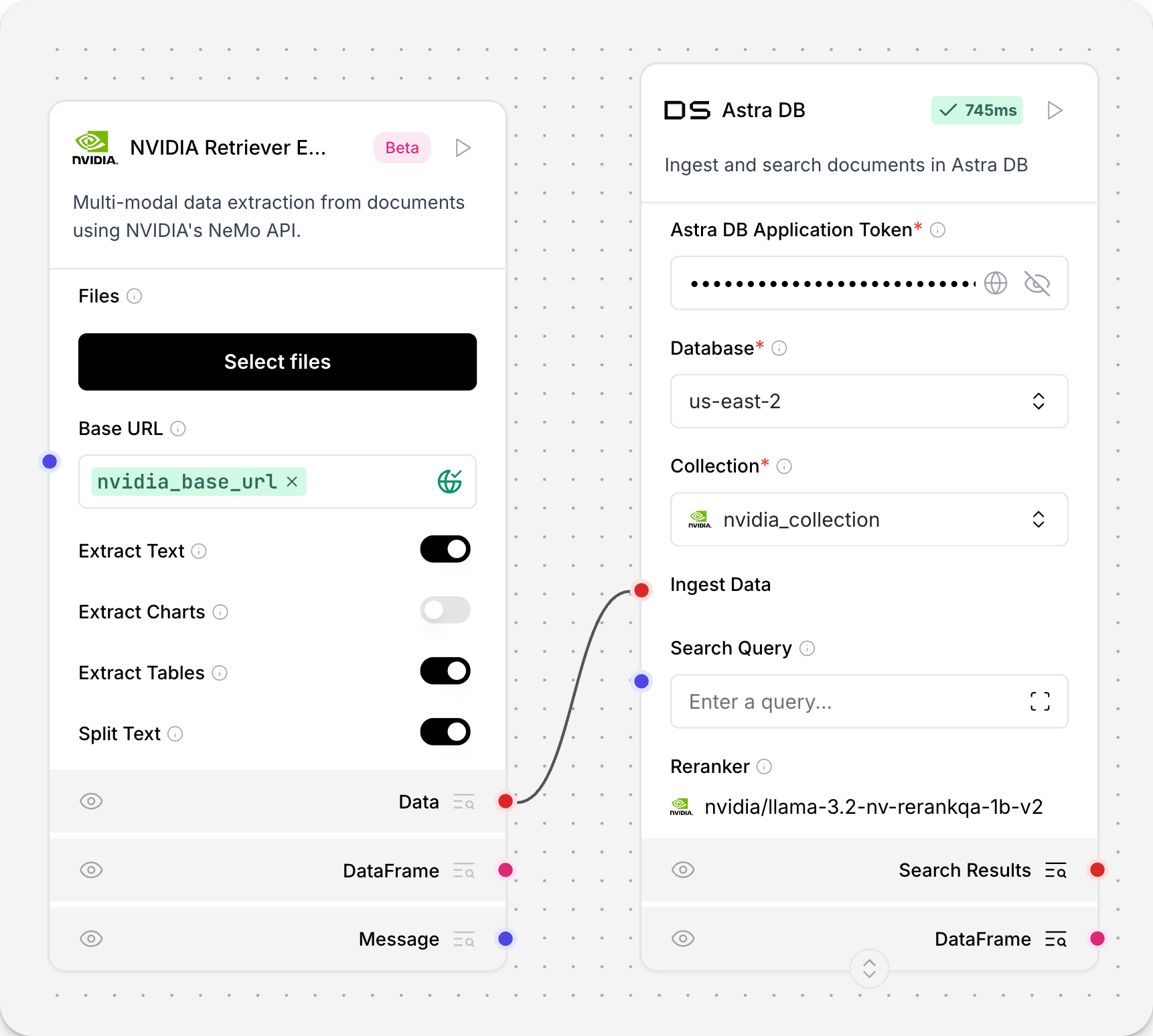
NVIDIA Retriever Extraction 组件参数
NVIDIA Retriever Extraction 组件具有以下参数。
有关更多信息,请参阅 NV-Ingest 文档。
Inputs
| Name | Display Name | Info |
|---|---|---|
| base_url | NVIDIA Ingestion URL | NVIDIA Ingestion API 的 URL。 |
| path | Path | 要处理的文件路径。 |
| extract_text | Extract Text | 从文档中提取文本。默认值:true。 |
| extract_charts | Extract Charts | 从图表中提取文本。默认值:false。 |
| extract_tables | Extract Tables | 从表格中提取文本。默认值:true。 |
| extract_images | Extract Images | 从文档中提取图像。默认值:true。 |
| extract_infographics | Extract Infographics | 从文档中提取信息图表。默认值:false。 |
| text_depth | Text Depth | 提取文本的层级。选项:'document', 'page', 'block', 'line', 'span'。默认值:page。 |
| split_text | Split Text | 将文本分割成较小的块。默认值:true。 |
| chunk_size | Chunk Size | 每个块的 token 数量。默认值:500。确保块大小与您的嵌入模型兼容。有关更多信息,请参阅由于块大小导致的标记化错误。 |
| chunk_overlap | Chunk Overlap | 与前一个块重叠的 token 数量。默认值:150。 |
| filter_images | Filter Images | 过滤图像(有关过滤条件的详细信息,请参阅高级选项)。默认值:false。 |
| min_image_size | Minimum Image Size Filter | 图像的最小宽度/长度(像素)。默认值:128。 |
| min_aspect_ratio | Minimum Aspect Ratio Filter | 允许的最小宽高比(宽度/高度)。默认值:0.2。 |
| max_aspect_ratio | Maximum Aspect Ratio Filter | 允许的最大宽高比(宽度/高度)。默认值:5.0。 |
| dedup_images | Deduplicate Images | 过滤重复的图像。默认值:true。 |
| caption_images | Caption Images | 使用 NVIDIA 标注模型为图像生成标题。默认值:true。 |
| high_resolution | High Resolution (PDF only) | 以高分辨率模式处理 PDF,以从扫描的 PDF 中获得更好的提取质量。默认值:false。 |
Outputs
NVIDIA Retriever Extraction 组件输出一个 Data 对象列表,其中每个对象包含:
text: 提取的内容。- 对于文本文档:提取的文本内容。
- 对于表格和图表:提取的表格/图表内容。
- 对于图像:图像标题。
- 对于信息图表:提取的信息图表内容。
file_path: 源文件名和路径。document_type: 文档类型,可以是text、structured或image。description: 内容的附加描述。
输出根据 document_type 的不同而变化:
-
document_type: "text"的文档包含:- 从文档中提取的原始文本内容,例如来自 PDF 或 DOCX 文件的段落。
- 直接存储在
text字段中的内容。 - 使用
extract_text参数提取的内容。
-
document_type: "structured"的文档包含:- 从表格、图表和信息图表中提取并处理以保留结构信息的文本。
- 使用
extract_tables、extract_charts和extract_infographics参数提取的内容。 - 从
table_content元数据处理后存储在text字段中的内容。
-
document_type: "image"的文档包含:- 从文档中提取的图像内容。
- 当启用
caption_images时,存储在text字段中的标题文本。 - 使用
extract_images参数提取的内容。